Introduction
A few years ago Library Archives Canada, Ian Milligan and I collected tweets from the 42nd Canadian Federal Election. Ian and wrote up a case study in Code4Lib Journal that took a look at the collection process, exploration of the dataset, and some context.
This past fall, the 43rd Canadian Federal Election occurred, and we collected tweets again. Instead of writing up the entire process for a journal publication again, I figured I’d revisit some of the methods we used last time to have a look at the dataset, and share some new methods I’ve picked up since then.
Feel free to hydrate the dataset and follow along. Don’t be afraid to build on, and expand the #elxn43 Jupyter Notebooks. Time permitting, I’d love to get around to extracting some keywords and hashtags along with timestamps, and plot them out to see how they evolved over the election period. So, there’s a lot more questions this dataset can be asked. I’d love to see what others come up with. So, have fun with it!
Overview
The dataset was collected with Documenting the Now’s twarc. It contains 2,944,525 tweet ids for #elxn43 tweets.
If you’d like to follow along, and work with the tweets, they can be “rehydrated” with Documenting the Now’s twarc, or Hydrator.
$ twarc hydrate elxn43-ids.txt > elxn43.jsonl
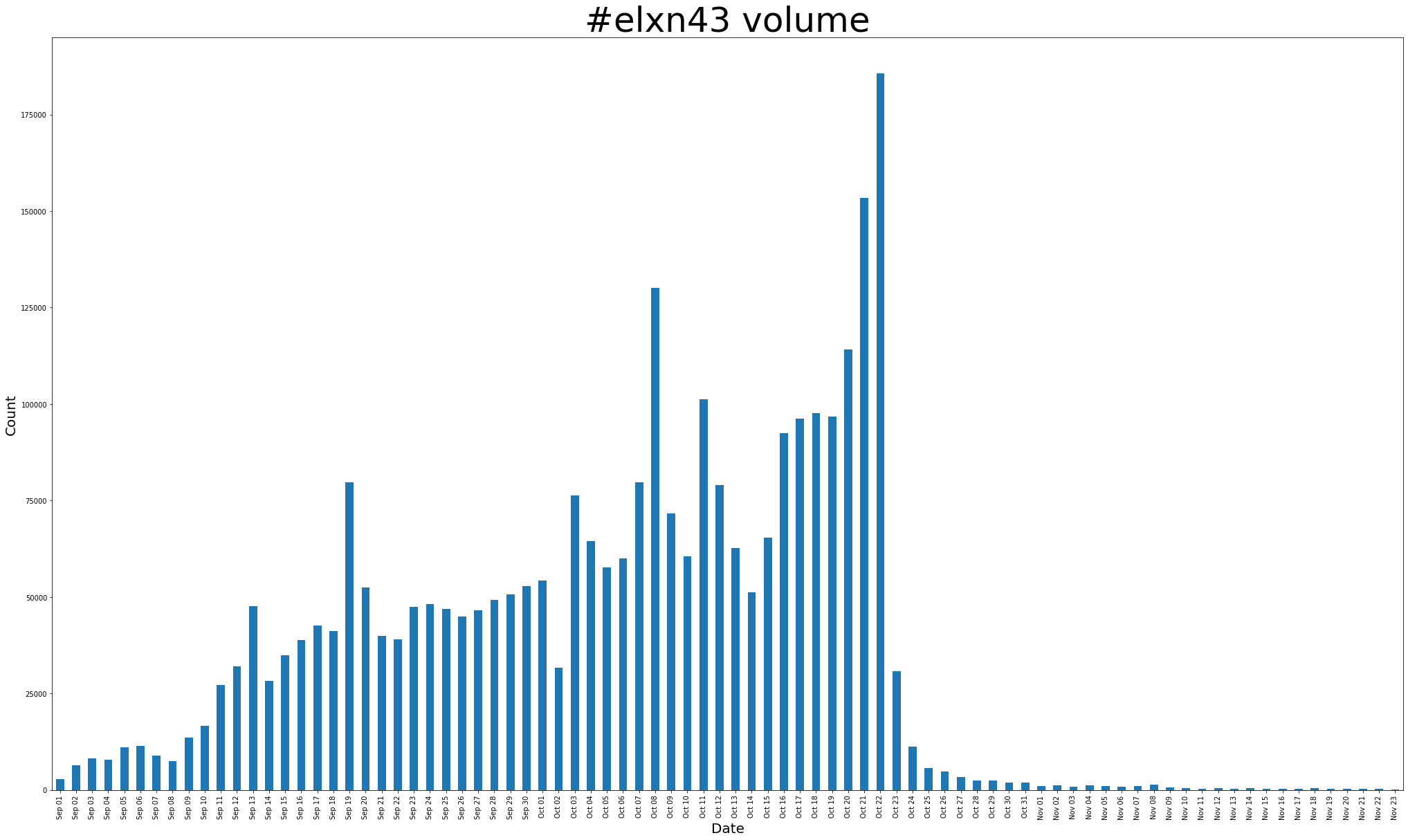
The dataset was created by collecting tweets from the the Standard Search API on a cron job every five days from September 9, 2019 - November 23, 2019.
Top tweeters
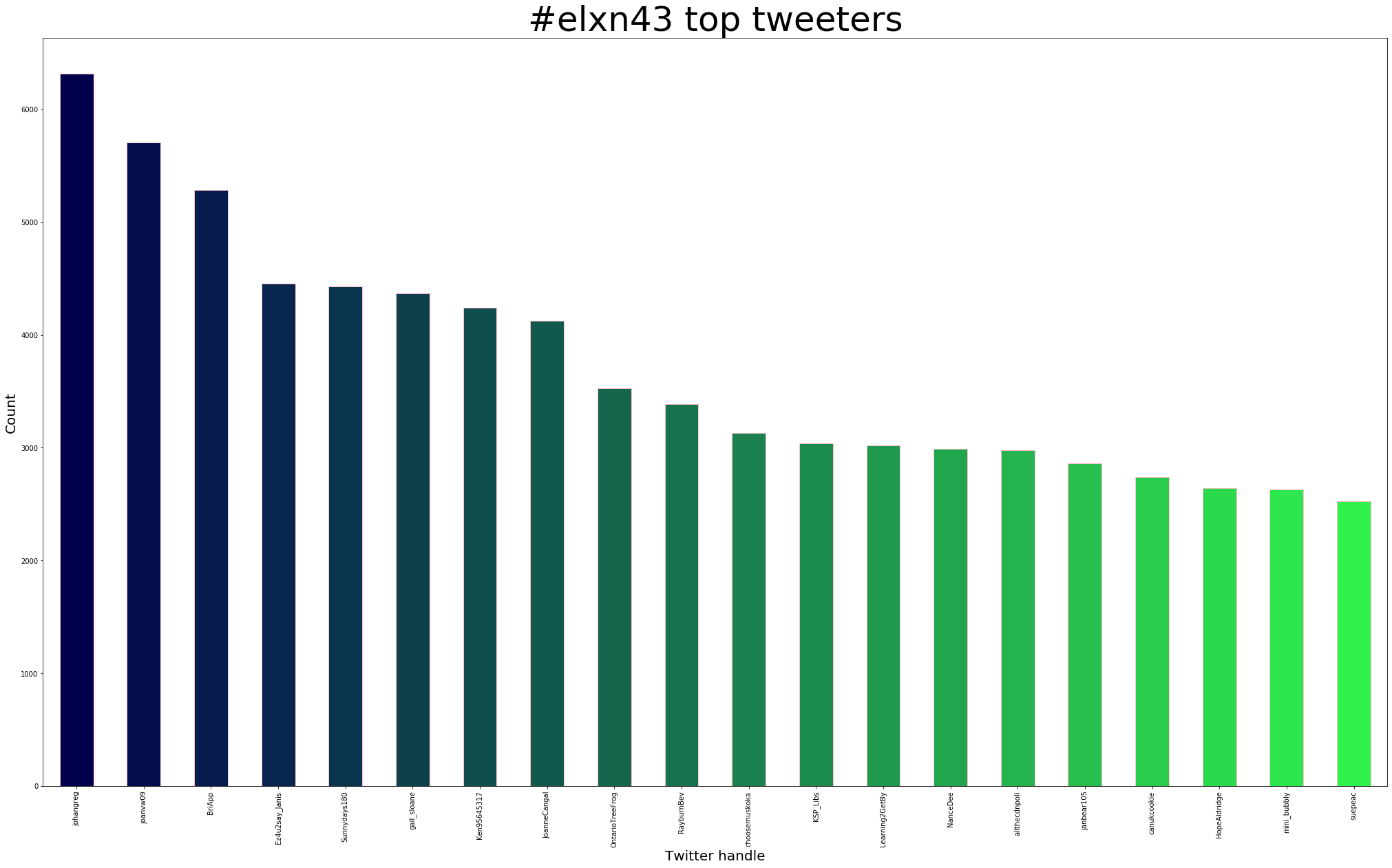
Using users.py from Twarc’s utilities, along with sort and uniq we can find out who the most prolific tweeters were:
$ python twarc/utils/users.py elxn43.jsonl > derivatives/elxn43-users.txt
$ cat elxn43-users.txt | sort | uniq -c | sort -nr > elxn43-users-counts.txt
$ head elxn43-users-counts.txt
- 6,319 Greg Johansen 🏳️🌈 🐓🍷 [johangreg]
- 5,705 Joanna 🇨🇦 🐔 🍷🍁☘️ [joanvw09]
- 4,455 Janis Sexton [Ez4u2say_Janis]
- 4,430 Sunnydays 🌅🌞🍁 [Sunnydays180]
- 4,368 Gail Sloane [gail_sloane]
- 4,243 Ken [Ken95645317]
- 4,125 🦂🌈Joanne 🌈🦂 [JoanneCangal]
- 3,530 Gray Tree Frog 🍊 [OntarioTreeFrog]
- 3,388 Bev Rayburn [RayburnBev]
- 3,042 KSP_Libs [KSP_Libs]
We can also take elxn43-users.txt, explore it further in a Jupyter Notebook, and plot the 20 most prolific tweeters:
Retweets
Using retweets.py from Twarc’s utilities, we can find the most retweeted tweets:
$ python twarc/utils/retweets.py elxn43.jsonl > derivatives/elxn43-retweets.txt
$ head elxn43-retweets.txt
1177737746414260224,11956
1184131458660651017,8335
1184894252343529473,5402
1178027994285260800,5173
1180539976876007425,4785
1186283726629507072,4436
1181369055929929728,4211
1186788390156623874,2917
1186475206665216000,2910
1184880719950155776,2797
From there, we can use append the tweet ID to https://twitter.com/i/status/ to see the tweet. Here’s the top three:
- 11,956
80,000+ #Vancouver
— Greenpeace Canada (@GreenpeaceCA) September 28, 2019
20,000+ #Victoria
500,000 #Montreal
10,000 #Halifax
4,000 #Edmonton
10,000 #Winnipeg
10,000 - 20,000 #Ottawa
15,000 - 50,000 #Toronto
People in Canada want #climateaction.
And they want it now. #climatestrike #FridaysForFurture #cdnpoli #elxn43 pic.twitter.com/FmhnAVP6QJ - 8,335
This is my last chance to make a difference. Please share this with your network and get out and vote! #whatsyourexcuse @justinpjtrudeau @andrewjscheer @jagmeetsingh @MaximeBernier @liberalca @cpc_hq @ndp @peoplespca @CanadianGreens #cdnpoli #Elxn43 #canpoli pic.twitter.com/xxfXxuOrEf
— Maddison (@MaddiYet) October 15, 2019 - 5,402
cancel #elxn43, he's already won pic.twitter.com/T6s90JV6a0
— sasha (@sashakalra) October 17, 2019
Top Hashtags
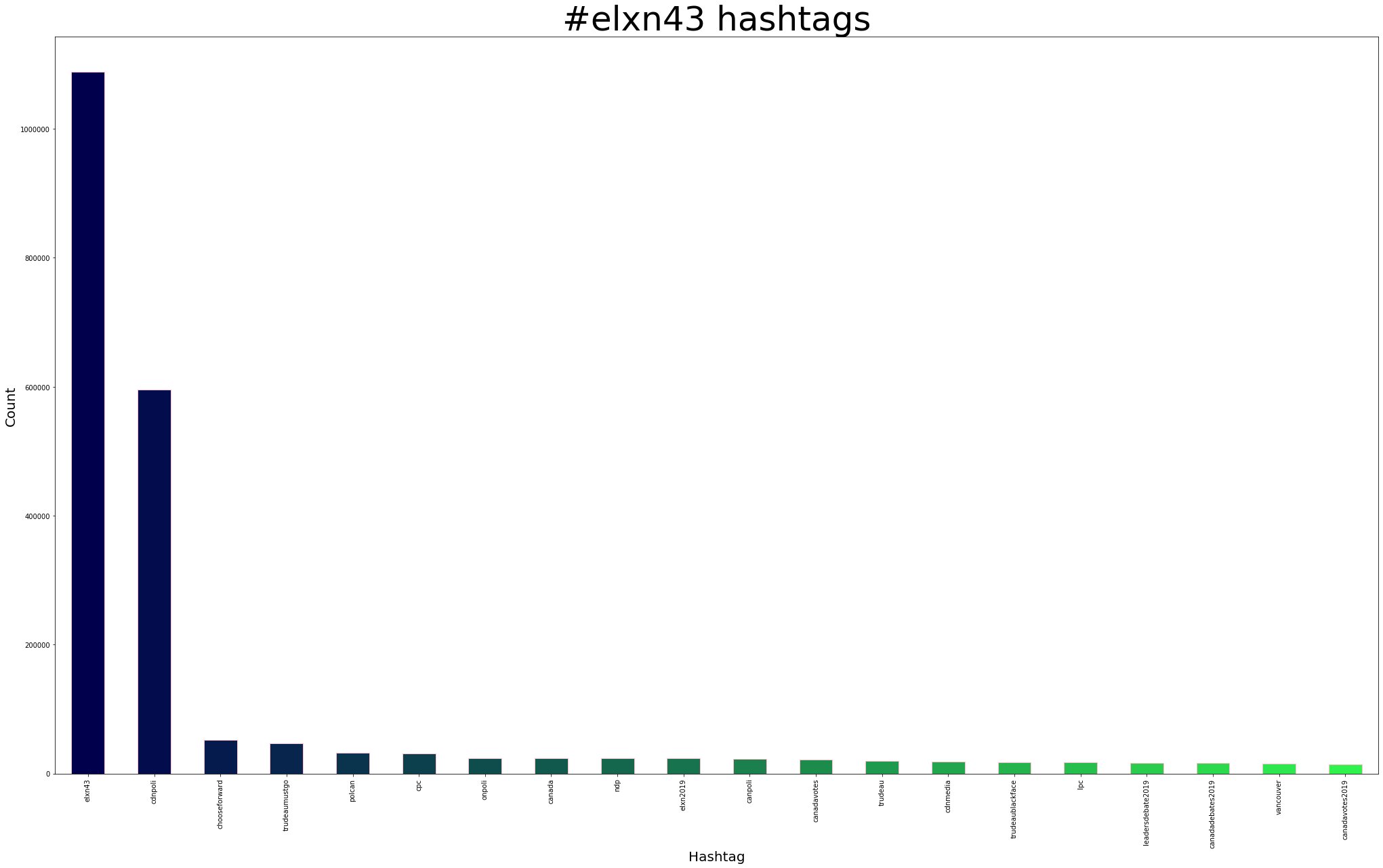
Using tags.py from Twarc’s utilities, we can find the most used hashtags:
$ python twarc/utils/tags.py elxn43.jsonl > derivatives/elxn43-hashtags.txt
$ head elxn43-hashtags.txt
- 1,088,235 #elxn43
- 595,287 #cdnpoli
- 52,488 #chooseforward
- 46,793 #trudeaumustgo
- 32,562 #polcan
- 31,056 #cpc
- 24,294 #onpoli
- 24,195 #canada
- 23,672 #ndp
- 23,386 #elxn2019
We can also take elxn43-tags.txt, explore it further in a Jupyter Notebook, and plot the 20 most popular hashtags:
Top URLs
Using urls.py from Twarc’s utilities, along with sort and uniq we can find out the most shared URLs:
$ python twarc/utils/urls.py elxn43.jsonl > derivatives/elxn43-urls.txt
$ cat elxn43-urls.txt | sort | uniq -c | sort -nr > elxn43-url-counts.txt
$ head elxn43-urls-counts.txt
- 4,906 http://bit.ly/2m0MYHI
- 1,191 https://montrealgazette.com/opinion/editorials/our-endorsement-best-choice-for-canada-is-andrew-scheer
- 1,100 https://twitter.com/BarackObama/status/1184528998669389824
- 993 http://bit.ly/2kT2W5W
- 835 https://www.thebeaverton.com/2019/10/voters-send-clear-message-of-ugh-fine-trudeau-again-i-guess/
- 814 http://cpcp.cc/GHK-RY
- 804 https://twitter.com/vote4robgill/status/1186228628675289088
- 791 https://www.theglobeandmail.com/politics/article-liberal-mp-involved-in-cannabis-start-up-did-not-publicly-disclose/
- 708 https://www.cp24.com/video?clipId=1807978&binId=1.1127680&playlistPageNum=1
- 697 http://Globalnews.ca
Looking at that list, you might notice a few URLs that come from a URL shortner service. Since 2015, a lot has changed with Twitter. Even though Twitter moved to 280 characters, and shortens URLs for us now, we’re still going to want to get a look at all the unique URLs, so let’s use Ed Summers’ unshrtn in conjunction with the unshrtn.py utility to unshorten those URLs, and get a true look at the URLs.
$ docker run -p 3000:3000 docnow/unshrtn
$ python twarc/utils/unshrtn.py elxn43.jsonl > elxn43_unshrtn.jsonl
$ python twarc/utils/urls.py elxn43_unshrtn.jsonl > derivatives/elxn43-unshrtn-urls.txt
$ cat elxn43-unshrtn-urls.txt | sort | uniq -c | sort -nr > elxn43-unshrtn-urls-counts.txt
$ head elxn43-unshrtn-urls-counts.txt
- 4,909 https://www.thepostmillennial.com/why-did-the-toronto-star-just-remove-a-high-quality-trudeau-blackface-video/
- 1,218 https://montrealgazette.com/opinion/editorials/our-endorsement-best-choice-for-canada-is-andrew-scheer
- 1,100 https://twitter.com/BarackObama/status/1184528998669389824
- 1,019 https://338canada.com/
- 996 https://www.thepostmillennial.com/trudeaus-ego-comes-at-too-high-a-price-for-the-liberals/
- 835 https://www.thebeaverton.com/2019/10/voters-send-clear-message-of-ugh-fine-trudeau-again-i-guess/
- 815 https://www.conservative.ca/cpc/justin-trudeau-high-carbon-hypocrite/
- 804 https://twitter.com/vote4robgill/status/1186228628675289088
- 791 https://www.theglobeandmail.com/politics/article-liberal-mp-involved-in-cannabis-start-up-did-not-publicly-disclose/
- 710 https://www.cp24.com/video?clipId=1807978
Adding URLs to Internet Archive
Do you know about the Internet Archive’s handy Save Page Now API?
Well, you could submit all those URLs to the Internet Archive if you wanted to.
You have be nice, and need to include a 5 second pause between each submission, otherwise your IP address will be blocked for 5 minutes!!
<h1>Too Many Requests</h1>
We are limiting the number of URLs you can submit to be Archived to the Wayback Machine, using the Save Page Now features, to no more than 15 per minute.
<p>If you submit more than that we will block Save Page Now requests from your IP number for 5 minutes.
</p>
<p>
Please feel free to write to us at info@archive.org if you have questions about this. Please include your IP address and any URLs in the email so we can provide you with better service.
</p>
You can use something like Raffaele Messuti’s example here.
Or, a one-liner if you prefer!
$ while read -r line; do curl -s -S "https://web.archive.org/save/$line" && echo "$line submitted to Internet Archive" && sleep 5; done < elxn43-urls.txt
I wonder what the delta is this time between collecting organizations, Internet Archive, and Tweeted URLs is?
Top media urls
Using media_urls.py from Twarc’s utilities, along with sort and uniq we can find out what the most shared media is:
$ python twarc/utils/media_urls.py elxn43.jsonl > derivatives/elxn43-media-urls.txt
$ cat elxn43-media-urls.txt | sort | uniq -c | sort -nr > elxn43-media-url-counts.txt
$ head elxn43-media-urls-counts.txt
You might notice a pattern here, we have the same media, with standardized dimensions since the most popular media seems to be video! That’s a big change from 2015’s #elxn42 😄
So let’s take the first 40 (head -n 40) to get a top 10 list:
- 4,778 https://video.twimg.com/ext_tw_video/1184894182088957952/pu/vid/540x960/tyDxSU6pjZU2EezW.mp4?tag=10
- 1,794 https://video.twimg.com/amplify_video/1183503880551849984/vid/720x720/oCeL-HdmcV1hvWvo.mp4?tag=13
- 1,127 https://video.twimg.com/amplify_video/1178429095501283335/vid/720x720/ZC-WTOxhCmLGCQ3W.mp4?tag=13
- 1,094 https://video.twimg.com/ext_tw_video/1173384916492541953/pu/vid/640x360/SC8n4_3aSC1nIodT.mp4?tag=10
- 943 https://video.twimg.com/ext_tw_video/1185771679357771776/pu/vid/640x360/eg7i4SAWbGpTUfrN.mp4?tag=10
- 937 https://video.twimg.com/amplify_video/1181635507639459841/vid/720x720/gGFnVQX-KUhfn9XD.mp4?tag=13
- 926 https://video.twimg.com/amplify_video/1178005064063037445/vid/720x720/DZsgqEz5SEUfCHds.mp4?tag=13
- 787 https://video.twimg.com/ext_tw_video/1181766345710538752/pu/vid/960x540/-1KWwUZQSks1a2Gn.mp4?tag=10
- 716 https://video.twimg.com/amplify_video/1185948578495291392/vid/640x360/qPpPYBk7Y5cfxzTG.mp4?tag=13
- 697 https://video.twimg.com/ext_tw_video/1177744072267706374/pu/vid/720x720/TiUsXl9Wnw0I_4_I.mp4?tag=10
Images
We looked a bit at the media URLs above. Since we have a list (elxn43-media-urls.txt) of all of the media URLs, we can download them and get a high level overview of the entire collection with a couple different utilities.
Similar to the one-liner above, we can download all the images like so:
$ while read -r line; do wget "line"; done < elxn43-media-urls.txt
You can speed up the process if you want with xargs or GNU Parallel.
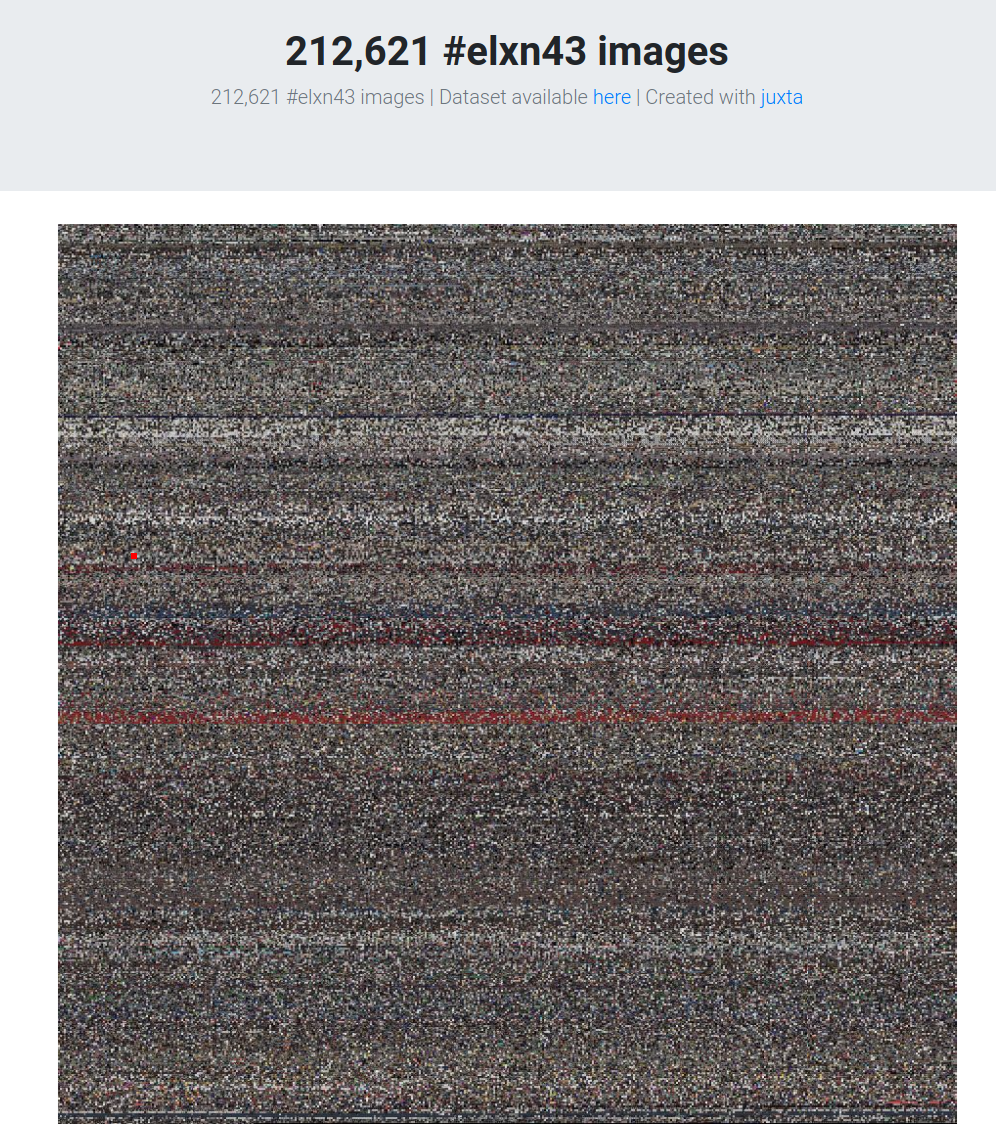
Juxta
Juxta is a really great tool that was created by Toke Eskildsen. I’ve written about it in the past, so I won’t go into an overview of it here.
That said, I’ve created a created a collage of the 212,621 images in the dataset. Click the image below to check it out.
If you’ve already hydrated the dataset, you can skip part of the process that occurs in demo_twitter.sh by setting up a directory structure, and naming files accordingly.
Setup the directory structure. You’ll need to have elxn43-ids.txt at the root of it, and hydrated.json.gz in the elxn43_downloads directory you’ll create below.
$ mkdir elxn43 elxn43_downloads
$ cp elxn43.jsonl elxn43_downloads/hydrated.json
$ gzip elxn43_downloads/hydrated.json
Your setup should look like:
├── elxn43
├── elxn43_downloads
│ ├── hydrated.json.gz
├── elxn43-ids.txt
From there you can fire up Juxta and wait while it downloads all the images, and creates the collage. Depending on the number of cores you have, you can make use of multiple threads by setting the THREADS variable. For example: THREADS=20.
$ THREADS=20 /path/to/juxta/demo_twitter.sh elxn43-ids.txt elxn43
Understanding the collage; you can follow along in the image chronologically. The top left corner of the image will be the earliest images in the dataset (September 10, 2019), and the bottom right corner will be the most recent images in the dataset (November 22, 2019). Zoom in and pan around! The images will link back to the Tweet that they came from.
PixPlot
Finally, we’ll take a look at PixPlot. This is a tool that comes from the Yale Digital Humanities Lab. It’s described as:
PixPlot facilitates the dynamic exploration of tens of thousands of images. Inspired by Benoît Seguin et al’s paper at DH Krakow (2016), PixPlot uses the penultimate layer of a pre-trained convolutional neural network for image captioning to derive a robost featurization space in 2,048 dimensions.
I’ve created a PixPlot of all 92,126 unique images. I had to do a little bit of work to get PixPlot to run on the dataset by converting all the media to jpegs. GNU Parallel comes in handy here.
$ ls -1 /path/to/images | parallel --jobs 24 --gnu "mogrify -format jpg -path /path/to/images_converted {}"
From there, I just ran PixPlot as per the instructions in the README, and waited for a long while.
$ python utils/process_images.py --image_files "/path/to/images_converted/*" --output_folder "/path/to/pixplot/output"

