Oh, I get by with a little help from my friends
Interdisciplinary Web Archive Collaboration
Nick Ruest
York University
Workshop on Quantitative Analysis and the Digital Turn in Historical Studies
February 27, 2019
Toronto, Canada
ruebot.net/presentations/histories-at-scale
We have a problem facing our collective cultural heritage.



















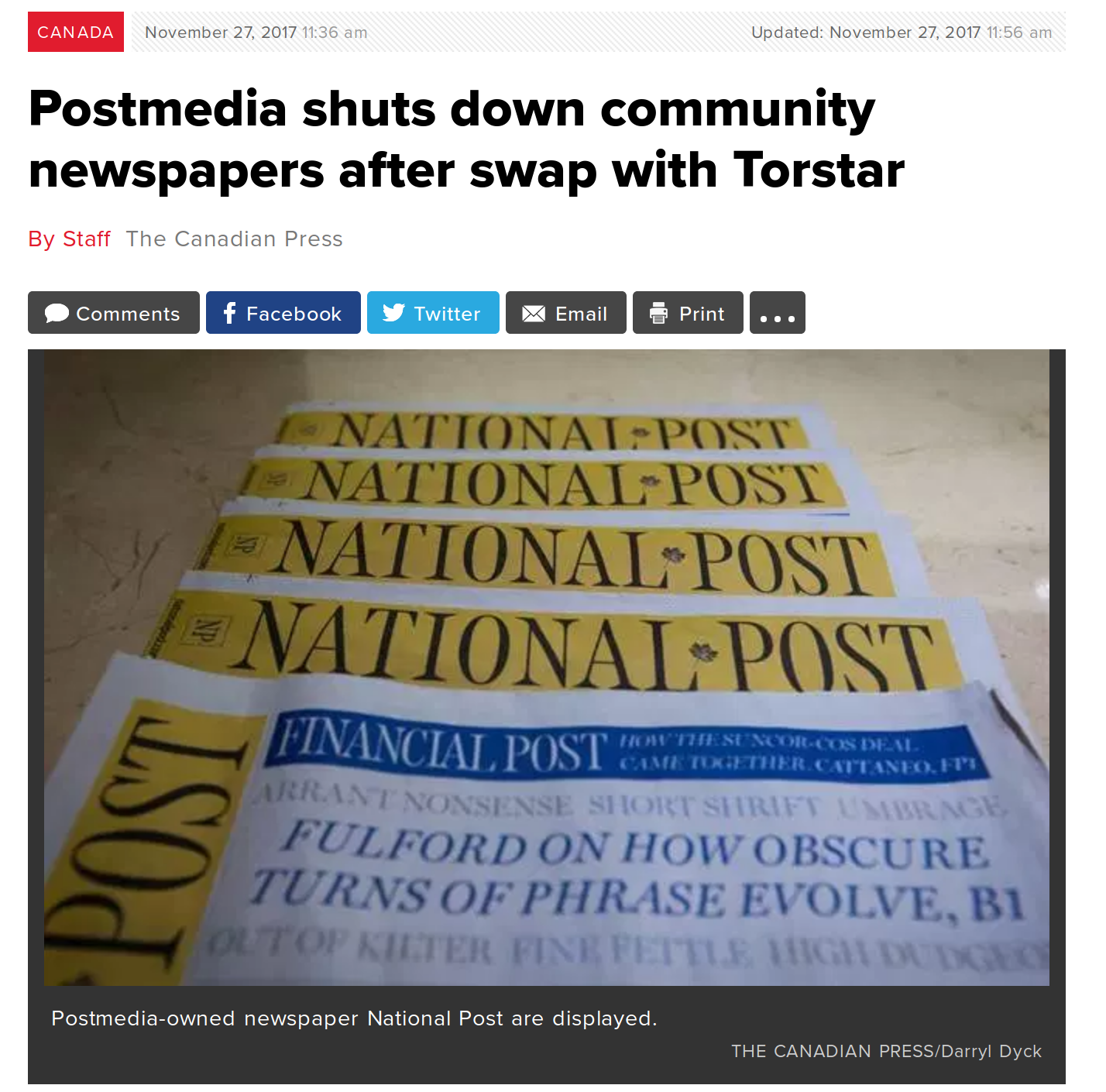
I won't delve into all the anxiety and horrors of digital preservation, and the urge to SAVE EVERYTHING.
but...
They're not the only ones doing this for the last 25yrs!
archive.today, Archive-It, Arquivo.pt: the Portuguese Web Archive, Bibliotheca Alexandrina Web Archive, DBpedia archive, DBpedia Triple Pattern Fragments archive, Canadian Government Web Archive, Croatian Web Archive, Estonian Web Archive, Icelandic web archive, Internet Archive, Library of Congress Web Archive, NARA Web Archive, National Library of Ireland Web Archive, National Records of Scotland, perma.cc, PRONI Web Archive, Slovenian Web Archive, Stanford Web Archive, UK Government Web Archive, UK Parliament's Web Archive, UK Web Archive, Web Archive Singapore, WebCite, Bayerische Staatsbibliothek

25 years of web archiving...
197,745 trials between 1674 and 1913
38 million user-built pages

4.1TB of WARCs
This is a scale that boggles the mind
Researcher's perspective
Scarcity
Scarcity
Abundance
Could one even study the 1990s and beyond without web archives?
…and the 1990s are history (as painful as it is to say).
And we have fears…
The decisions we make today will lay the foundations for how we work with born-digital cultural heritage.
We need infrastructure and tools.
But what will they look like?

Our Nightmare
Historians, librarians, and archivists rely uncritically on date-ordered or algorithmically-ranked keyword search results, putting them at mercy of search algorithms they do not understand.
We can't let the Blackbox write our histories.
Right now, to use web archives you have to really want to use them.
i.e., you need to be an expert
We want web archives to be used on page 153 of a random book!
So, how you gonna do that?
Interdisciplinary Collaboration






Our Goals
- Create relatively easy-to-use tools;
- Create tools that are UNDERSTANDABLE - no black boxes;
- Create tools that can push forward research in history, library/archives, and computer science;
- Help people use these tools, and inspire research & creativity with datathons.
We want to help people unleash their web archives!

How (internally)?
If you're honest and frank, it works.
Communication: identify expertise, be honest about time, and minimize ego
Scope: no one person can do all this. You have to work together if you really want to get answers.
specifications
frameworks
writing
documentation
community building
production platforms
sustainability
Academic Currency
How (externally)?
Tools & Community!
Lowering the barriers to entry so that humanists, librarians, and archivists can interact with large-scale web archive data, in a transparent way.
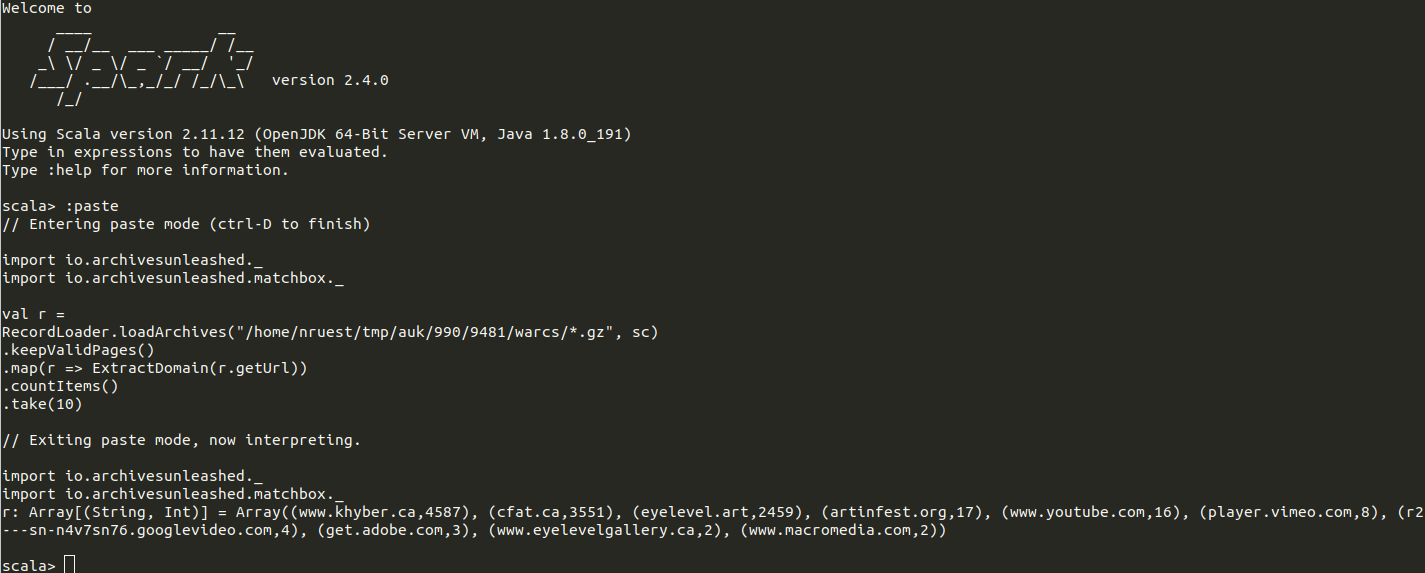
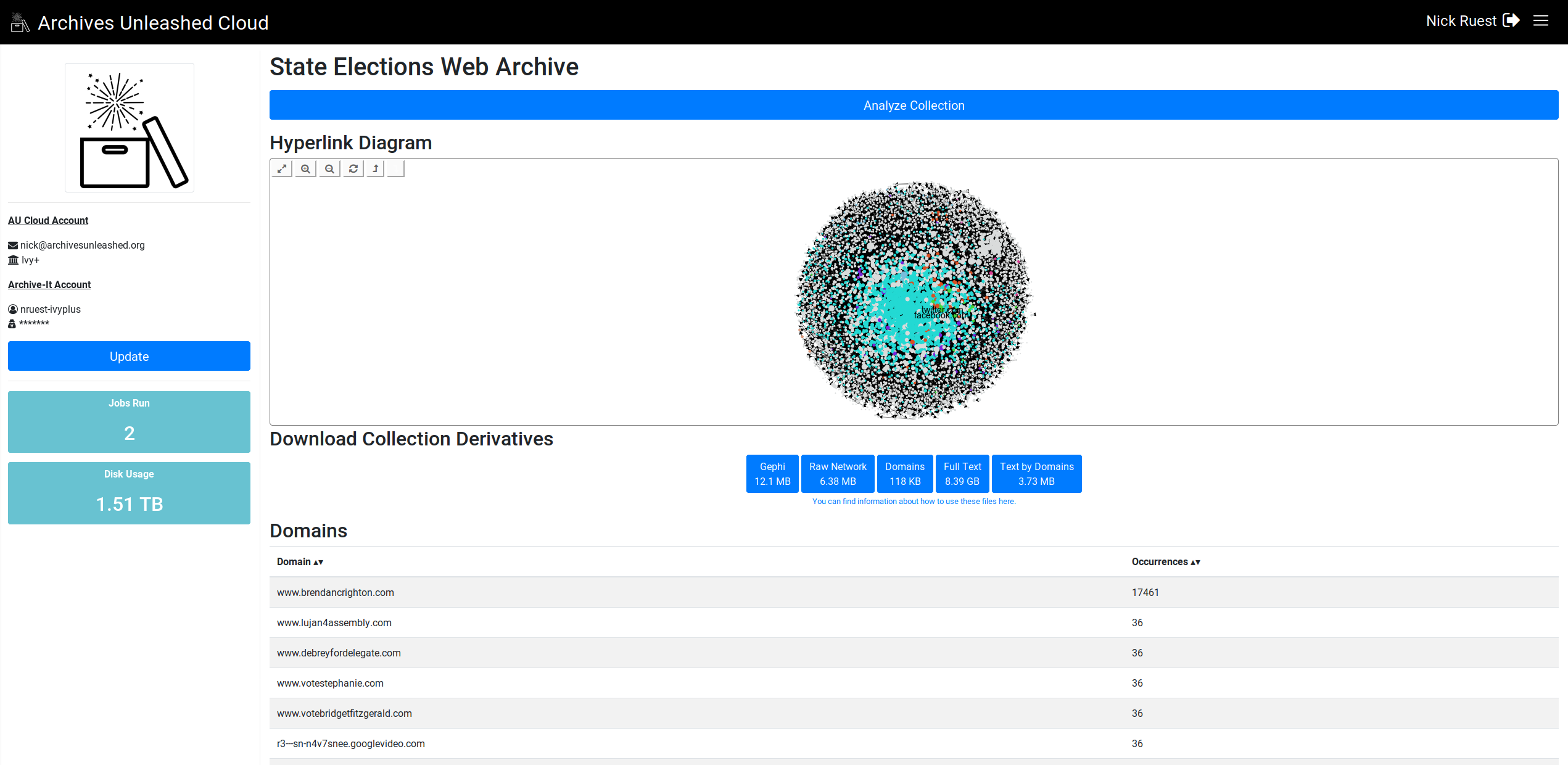
What if we had periodic gatherings where colleagues could get background information, learn how to use these tools, and work on a small project with other colleagues?

Maybe web archives aren't that boutique.
They can speak to a broader audience, and you can imagine how to use them!
So, hopefully, researchers can cite web archives on page 153 of a book without needing to be an expert!




