This past week Compute Canada provided us with resources to setup our Solr Cloud instance for WALK and Archives Unleashed. We were able to get things setup relatively quickly thanks to a bit of preparation and practice on our local machines in the previous weeks. Once everything was setup (5 virtual machines total; 4 Solr Cloud nodes and one indexer – details below), we started benchmarking webarchive-discovery and our Solr Cloud setup with GNU Parallel.¹
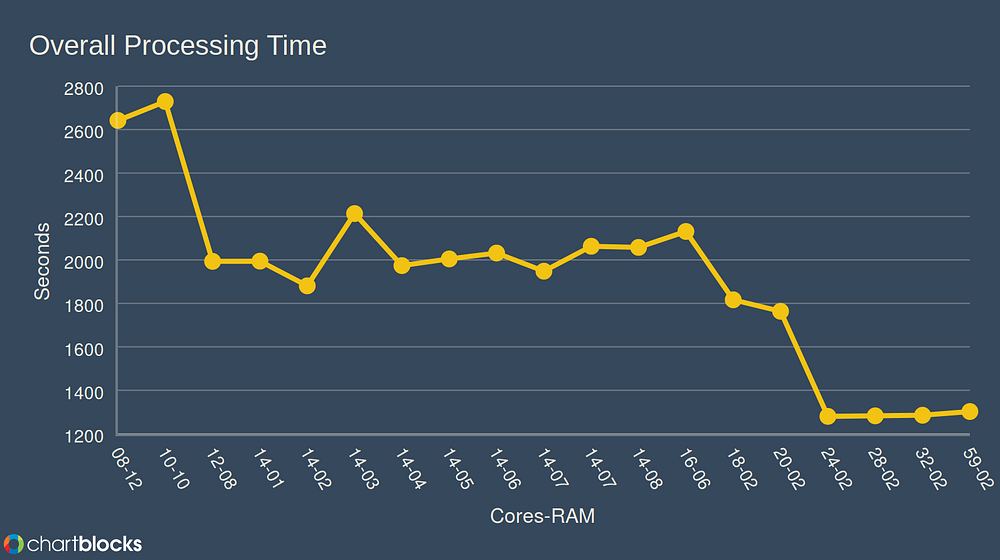
Overall this process took about a day to complete. We selected a relatively small collection from one of our Web Archives for Longitudinal Knowledge (WALK) partners. Described in detail below, the collection had more WARCs than number of CPU cores on our indexer, and jobs took around 30 minutes to complete. In our tests, we focused on three main areas: varying the number of jobs and RAM, varying RAM and keeping jobs consistent, and running more jobs that CPU cores available. In the future, we would like to do a more rigorous examination. For each run we deleted the Solr index and then started again, and used webarchive-discovery at this commit.
The command we ran each time was a variation of the command below, with only --jobs, -Xmx, and the log filename modified each time.
$ time find /data/727/4114/warcs -iname "*.gz" -type f | parallel --jobs 16 --gnu "java -Xmx6g -Djava.io.tmpdir=/mnt/tmp -jar /home/ubuntu/warc-indexer.jar -i 'Simon Fraser University Library' -n 'SFU Affiliated Conferences/Institutes' -u '4114' -s http://192.168.32.20:8983/solr/walk {} > $(basename {})-16-06.log"
Below is a summary table of all 19 of the jobs run. Each summary includes the output from time, as well as the number of Solr docs at the end of the run, webarchive-discovery log output from the same file, and the time it took to run on that file. Overall we found that running more jobs than cores available is not only safe, but leads to the fastest results. As you can see from the chart below, running more jobs than cores available had significant performance advantages over several of the other configurations, and there appears to be a sweet spot at 24–32 jobs with 16 cores.