Community
Some pretty exciting stuff has been happening lately in the Islandora community. Earlier this year, Islandora began the transformation to a federally incorporated, community-driven soliciting non-profit. Making it, in my opinion, and much more sustainable project. Thanks to my organization joining on as a member, I’ve been provided the opporutinity to take part in the Roadmap Committe. Since I’ve joined, we have been hard at work creating transparent policies and processes software contributions, licenses, and resources. Big thanks to the Hydra community for providing great examples to work from!
I signed my first contirbutor licence agreement, and initiated the process for making the Web ARChive Solution Pack a canonical Islandora project, subject to the same release management and documentation processes as other Islandora modules. After working through the process, I’m happy to see that the Web ARChive Solution Pack is now a canonical Islandora project.
Project updates
I’ve been slowly picking off items from my initial todo list for the project, and have solved two big issues: indexing the warcs in Solr for full-text/keyword searching and creating and index of each warc.
Solr indexing was very problematic at first. I ened up having a lot of trouble getting an xslt to take the warc datastream and give it to FedoraGSearch, and in-turn to Solr. Frustrated, I began experimenting with newer versions of Solr, which thankfully has Apache Tika bundled, thereby allowing for Solr to index basically whatever you throw at it.
I didn’t think our users wanted to be searching the full markup of a warc file. Just the actual text. So, using the Internet Archives’ Warctools and @tef’s wonderful assistance, I was able to incorporate warcfilter into the derivative creation.
$ warcfilter -H text warc_file > filtered_file
You can view an example of the full-text searching of warcs in action here.
In addition to the full-text searching, I wanted to provided users with a quick overview of what is in a given capture, and was able to do so by also incorporating warcindex into the derivative creation.
$ warcindex warc_file > csv_file
#WARC filename offset warc-type warc-subject-uri warc-record-id content-type content-length
/extra/tmp/yul-113521_OBJ.warc 0 warcinfo None <urn:uuid:588604aa-4ade-4e94-b19a-291c6afa905e> application/warc-fields 514
/extra/tmp/yul-113521_OBJ.warc 797 response dns:yfile.news.yorku.ca <urn:uuid:cbeefcb0-dcd1-466e-9c07-5cd45eb84abb> text/dns 61
/extra/tmp/yul-113521_OBJ.warc 1110 response http://yfile.news.yorku.ca/robots.txt <urn:uuid:6a5d84d1-b548-41e4-a504-c9cf9acfcde7> application/http; msgtype=response 902
/extra/tmp/yul-113521_OBJ.warc 2366 request http://yfile.news.yorku.ca/robots.txt <urn:uuid:363da425-594e-4365-94fc-64c4bb24c897> application/http; msgtype=request 257
/extra/tmp/yul-113521_OBJ.warc 2952 metadata http://yfile.news.yorku.ca/robots.txt <urn:uuid:62ed261e-549d-45e8-9868-0da50c1e92c4> application/warc-fields 149
The updated Web ARChive SP datastreams now look like so:
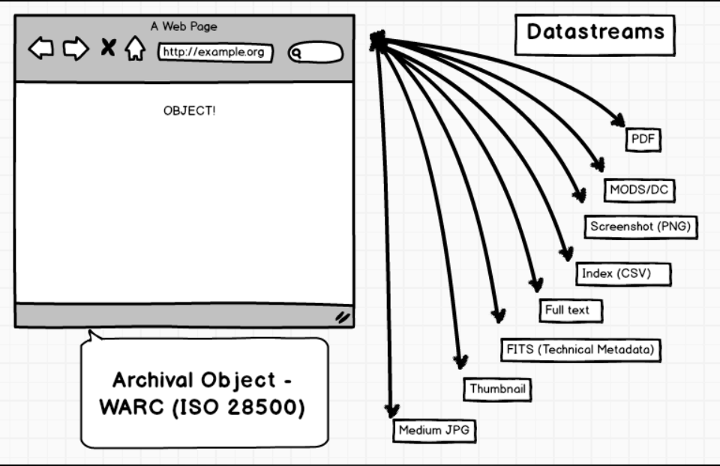
One of my major goals with this project has been integration with a local running instance of Wayback, and it looks like we are pretty close. This solution might not be the cleanest, but at least it is a start, and hopefully it will get better over time. I’ve updated the default MODS form for the module so that it better reflects this Library of Congress example. The key item here is the ‘url’ element with the ‘Archived site’ attribute.
<location>
<url displayLabel="Active site">http://yfile.news.yorku.ca/</url>
<url displayLabel="Archived site">http://digital.library.yorku.ca/wayback/20131226/http://yfile.news.yorku.ca/</url>
</location>
Wayback accounts for a date in its url structure ‘http://digital.library.yorku.ca/wayback/**20131226**/http://yfile.news.yorku.ca/' and we can use that to link a given capture to its given dissemination point in Wayback. Using some Islandora Solr magic, I should be able give that link to a user on a given capture page.
We have automated this in our capture and preserve process: capturing warcs with Heritrix, creating MODS datastreams, and screenshots. This allows us to batch import our crawl quickly and efficiently.
Hopefully in the new year we’ll have a much more elegant solution!
