Originally posted here.
Introduction
A few of the Archives Unleashed team members have a pretty in-depth background of working with Twitter data. Jimmy Lin spent some time at Twitter during an extended-sabbatical, Sam Fritz spent some time working with members of the Social Media Lab team previous to joining the Archives Unleashed Project, and Ian Milligan and I have done a fair bit of analysis and writing on our process of collecting and analyzing Canadian Federal Election tweets.
Early-on, and up until earlier this year, the Archives Unleashed Toolkit had functionality built in for reading Twitter data into RDDs, and processing them with a number of small methods that overlapped a bit with the utilities that twarc ships with. In an effort to simplify the Toolkit’s codebase and dependencies, we removed all of that functionality. Though, it was not to be forgotten. It lives on (for now!) as a stale branch. When the tweet analysis functionality was implemented, it was still pre-Apache Spark 2.0; pre-DataFrame ease. This made working with the data, and expanding the tweet analysis section of the codebase a bit tedious.
Use case
A lot of Twitter data analysis is going to involve trends over time. This means the datasets that are being worked with are going to get larger and larger over time. Which means working with and processing data from Twitter is going to get more and more difficult over time. Sounds like a perfect use case for Apache Spark, eh?
A few of the datasets that I’ve collected from Twitter have tweet counts well over 10 million. In the past, analysis basically consisted of firing up screen or tmux and just waiting as I processed the datasets. This is a completely practical solution. You just have to be patient, and have stable and reliable computing resources. Though, at a certain point, as datasets scale or patience wanes, you really start thinking that there has to be a better way do this this! 😄
All the time spent waiting for tweet data analysis jobs to complete, spending my time working on the Archives Unleashed Toolkit’s new DataFrame functionality, and processing many, many, many terabytes of web archives with the Archives Unleashed Cloud, got me really thinking about using Spark to process tweets again.
Working with newer versions of Spark, I took notice of the a really convenient Data Sources API that make loading something like line-oriented JSON from Twitter into Spark, and transforming it into a DataFrame with an inferred schema REALLY easy.
val tweets = "/path/to/tweets.jsonl"
val tweetsDF = spark.read.json(tweets)
That’s it! You can see the full inferred schema printed and example printed out here.
So, if it’s that simple to load tweets in as a DataFrame, and it opens up that whole world of working with tweets in a SQL-like manner, it has to be pretty dead simple to replicate a lot of the normal processing utilities used to do basic analysis on a collection, right?
YUP!
val tweets = "/path/to/tweets.jsonl"
val tweetsDF = spark.read.json(tweets)
tweetsDF.select($"id_str").show(5)
+-------------------+
| id_str|
+-------------------+
|1201505319257403392|
|1201505319282565121|
|1201505319257608197|
|1201505319261655041|
|1201505319261597696|
+-------------------+
only showing top 5 rows
Look at that!
What if we started abstracting those select methods out into a library?
Hello twut!
Similar to the Archives Unleashed Toolkit, twut, or Tweet Archives Unleashed Toolkit is a library (or package) for Apache Spark. It currently provides helper methods for a few processes that are used in basic analysis and statistic gathering on line-oriented JSON collected from a variety of Twitter APIs.
What does it do?
- Dehydration (tweet id extraction)
import io.archivesunleashed._
val tweets = "src/test/resources/10-sample.jsonl"
val tweetsDF = spark.read.json(tweets)
ids(tweetsDF).show(10, false)
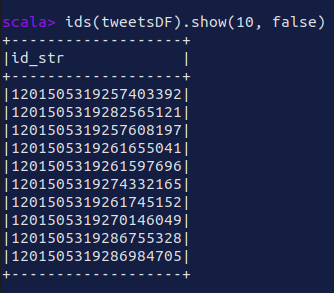 |
|---|
| twut Tweet ID extraction |
- Extract user info such as
favourites_count,followers_count,friends_count,id_str,location,name,screen_name,statuses_count, andverified
import io.archivesunleashed._
val tweets = "src/test/resources/10-sample.jsonl"
val tweetsDF = spark.read.json(tweets)
userInfo(tweetsDF).show(2, false)
 |
|---|
| twut Tweet User Info |
- Extract tweet text
import io.archivesunleashed._
val tweets = "src/test/resources/10-sample.jsonl"
val tweetsDF = spark.read.json(tweets)
text(tweetsDF).show(10, false)
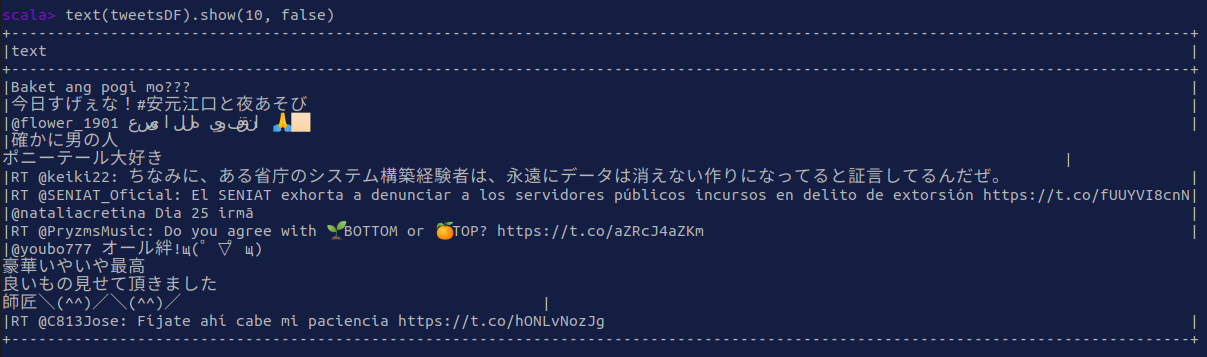 |
|---|
| twut tweet text |
- Extract tweet times
import io.archivesunleashed._
val tweets = "src/test/resources/10-sample.jsonl"
val tweetsDF = spark.read.json(tweets)
times(tweetsDF).show(10, false)
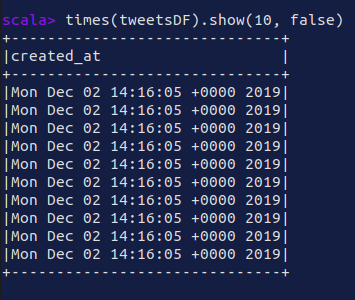 |
|---|
| twut tweet times |
Benchmarks
There are a lot of different options to work with data from Twitter since it is just line-oriented JSON. Pick your language. Pick your tool. Pick your platform. There’s a wealth of them out there to get the job done. In this case, I’m picking a few that I am most familiar with in order to illustrate the use case for creating a Apache Spark library for working with large Twitter datasets. Let’s look at a simple benchmark between three tools that extract the ids of tweets, so those datasets — one small, and one large — can be shared and rehydrated.
- Extracting tweet ids using
jq:
cat tweets.jsonl | jq -r .id_str > ids.txt
twarc deydrate tweets.jsonl > ids.txt
ids(tweetsDF).write.csv("path/to/output")
n.b. the twut benchmark test also includes the Spark startup, and loading the tweets in as a DataFrame costs.
Small dataset
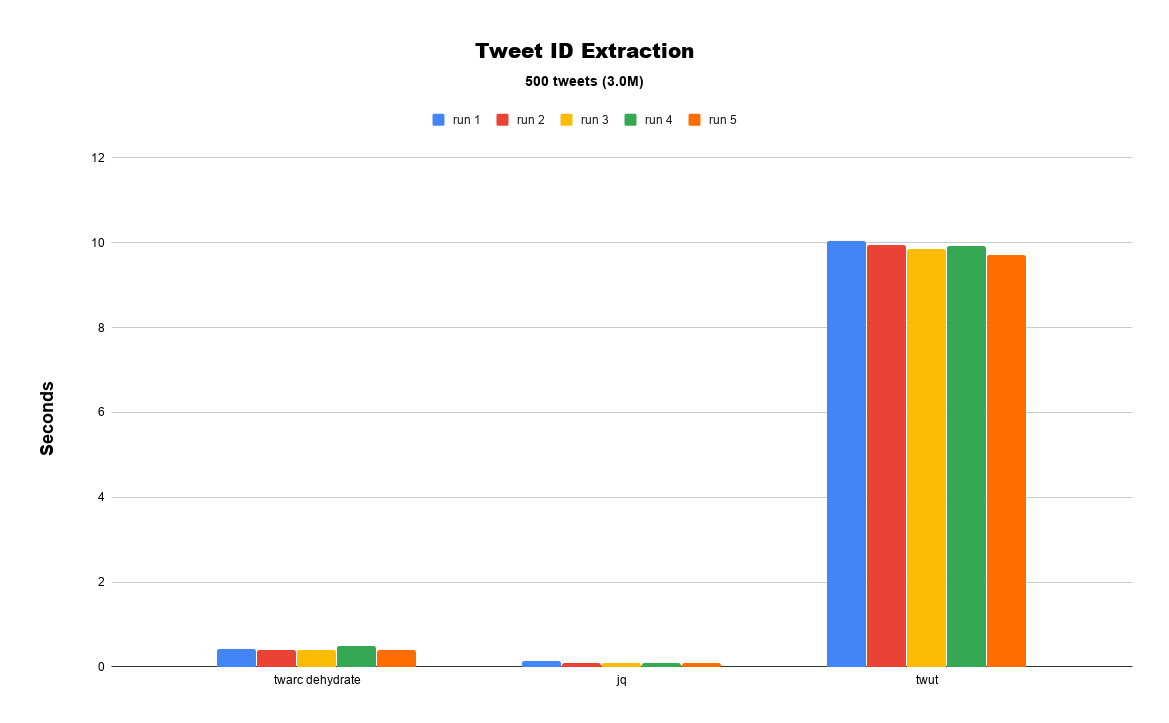 |
|---|
| Benchmark over a small collection |
The first test that I ran uses a small dataset of 500 tweets (3.0M) which was procured from the Twitter Sample API using the sample command in twarc.
Each command from the tools was run 5 times over the dataset, and times were collected with /usr/bin/time. Example:
/usr/bin/time --verbose -o ~/twut-benchmark/times/jq_time-01.txt
As is apparent in the figure above, on a really small dataset, jq and twarc dehydrate are going to be leaps and bounds faster than twut.ids. jq and twarc dehydrate are both able to extract the ids in under a second (0.422s and 0.108s respectively). Whereas twut.ids is almost 100x slower! That’s not good, but this also time takes into account the start-up costs of firing up Apache Spark, reading in the tweets as an Apache Spark Data Source, converting the line-oriented JSON tweets into a DataFrame, and finally running the id extraction.
Large dataset
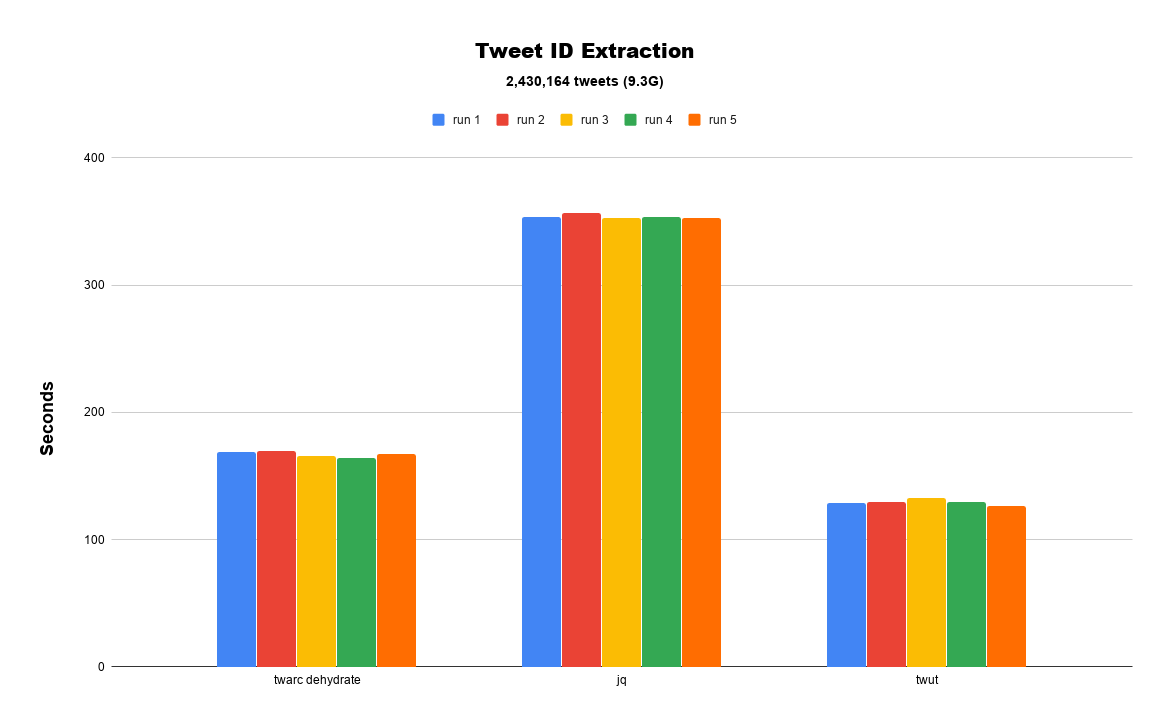 |
|---|
| Benchmark over a large collection |
The second test I ran uses a relatively large dataset of 2,420,164 tweets (9.3G) directed at @realDonaldTrump (NSFL!). Tweets were collected using the search command in twarc. The full dataset is available here.
Looking at the figure above, we can begin to see the advantages of using Apache Spark to process a dataset like this. twut.ids is able to process the dataset in just over two minutes (129.17s) on average, and twarc dehydrate is slightly slower at just under three minutes (167.138s). That time difference between the two should scale even more in the favour of twut and Spark as the size of the dataset grows. Lastly, and surprisingly, jq is the slowest at just under six minutes (353.73s). Though, in fairness to jq, it can be used in conjunction with xargs or GNU parallel to really sped things up.
If you look closer at the output of time, you can really get a sense of much computing resources each is able to use by looking at the “Percent of CPU this job got.”
jq— 4%twarc dehydrate— 99%twut.ids— 1012.2%
Gotta love Spark taking advantage of all available resources that are available!
What’s next?
I’ve just started working on the project in the past week, so it’s really rough around the edges, and could use a lot of improvement. I’m thinking a fair bit about adding some filter methods like extracting out all the tweets from verified users, or removing all the retweets. Or, putting on my archivist hat, and looking at twut as a finding aid utility. I also need to get the PySpark side of things sorted out, so you just fire up a Jupyter Notebook (with PySpark), and hack away.
There’s definitely a whole lot more that can be done here, and I am really curious if folks feel this is a useful project, and worth putting more time into. Let me know what you think in Slack or on the GitHub repo. It’d be nice to hear if this is useful 😃
