Originally posted here.
I’ve been thinking a lot lately about how the Archives Unleashed Toolkit is a great finding aid utility for web archive collections, and should be in the toolbox for any web archivist.
So, a finding aid. How could we create a finding aid for a web archive collection with relatively minimal labour?
The Society of American Archivists define a finding aid as:
A tool that facilitates discovery of information within a collection of records.
A description of records that gives the repository physical and intellectual control over the materials and that assists users to gain access to and understand the materials.
What are current practices? Generally speaking, most web archive collections from institutions such as national libraries, government organizations, or universities will have a set of descriptive metadata about a collection. This is often framed around Dublin Core, and is arguably a “minimal finding aid.” It is useful, and usually what can be done given time, budget, and labour constraints.
With the Archives Unleashed Toolkit, we can create a more robust finding aid. But, what should it be? Currently, we have four sets of what we’ve called scholarly derivatives of web archives that are produced with the Archives Unleashed Cloud. With each of the derivatives, we also provide extensive tutorials that walk through use cases for scholarly analysis.
Full Text
We provide a txt file, that’s comma delimited (basically a CSV file 😄). Each website within the web archive collection will have its full text presented on one line, along with information around when it was crawled, the name of the domain, and the full URL of the content
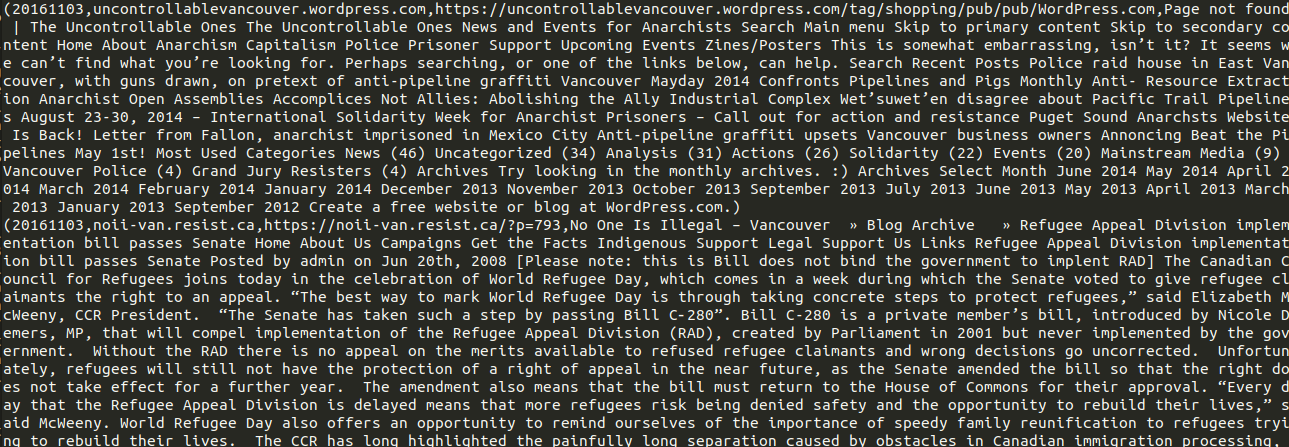 |
|---|
| Sample full-text aut output |
Domains CSV
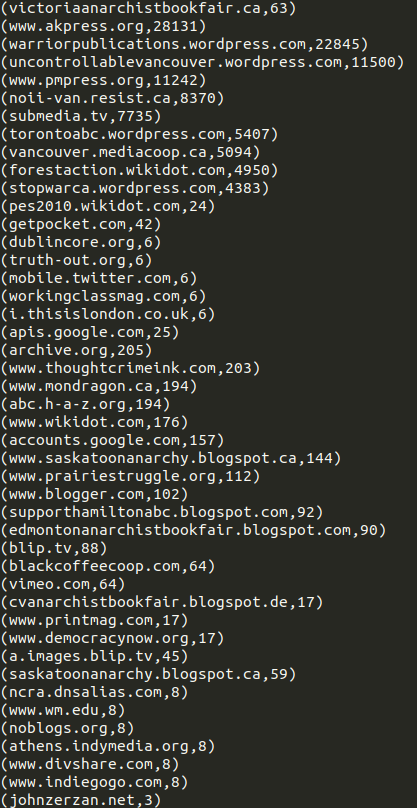 |
|---|
| Sample full-urls aut output |
Text by Domain
We provide a ZIP file containing ten text files (see Full Text derivative above) corresponding to the full-text of the top ten domains.
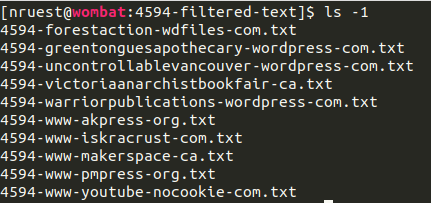 |
|---|
| Sample extracted filtered-text.zip output |
Gephi & Raw Network Files:
Two different network files (described below) are also provided. These files are useful to discovering how websites link to each other.
Gephi file, which can be loaded into Gephi. It will have basic characteristics already computed and a basic layout.
Raw Network file, which can also be loaded into Gephi. You will have to use the network program to lay it out yourself.
 collection](https://cdn-images-1.medium.com/max/5008/1*GEEtgFRp8aGc2RxU0oZRRg.png) |
|---|
| Hyperlink Diagram of University of Victoria’s Anarchist Archives collection |
In addition to the set of scholarly derivatives the toolkit can produce, we have also improved and expanded upon our DataFrame implementation in the most recent release of the Archives Unleashed Toolkit. If you’re familiar with CSV files, then you’ll be right at home with DataFrames!
You can now produce a variety of DataFrames of a web archive collection with the toolkit, that can be exported directly to CSV files.
You can produce a list of domains or a hyperlink network.
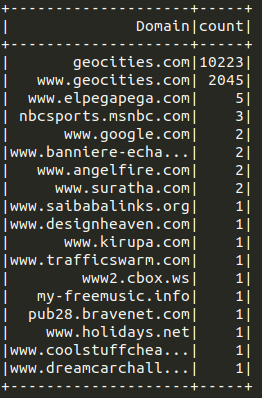 |
|---|
| List of domains example output in a DataFrame |
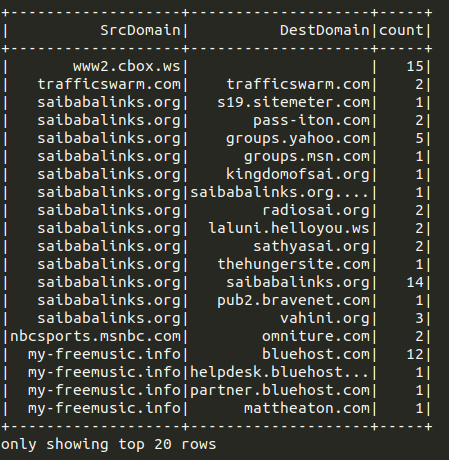 |
|---|
| Hyperlink network example output in a DataFrame |
You can also gather information on a variety of binary types in a web archive collection. We current support audio, images, pdf, presentation program files, spreadsheets, text files, videos, and word processor files. Each of these methods allows you to extract:
the url of the binary;
the filename of the binary;
the extension of the binary;
the MimeType identified by the web server, and by Apache Tika;
height and width of a image binary;
md5 hash of the binary;
and the raw bytes of the binary.
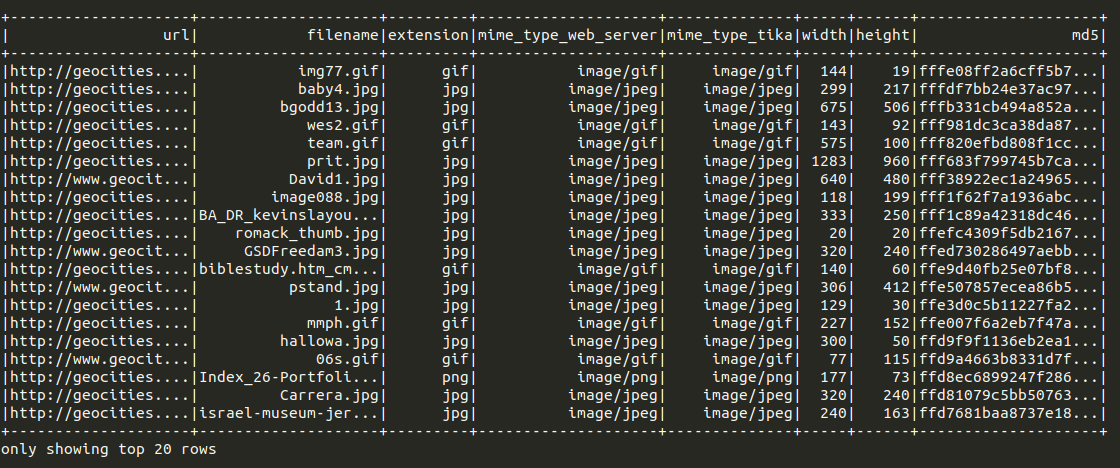 |
|---|
| Image analysis example output in a DataFrame |
What does all this mean?
If a given institution has an Archive-It subscription, they could generate a set of derivatives for their web archive collections with the Archives Unleashed Cloud. If they don’t have an Archive-It subscription, or want to do the analysis on their own with the Toolkit, and have the storage and compute resources available to run analysis on their web archive collections, we have a ready set of documented scripts available in the “cookbook” section of our documentation now.
I’m curious from an archivist’s perspective, what should make up a finding aid for a web archive collection? Is descriptive metadata for a collection sufficient? Does a combination of descriptive metadata for a collection, plus some combination of analysis with the Archives Unleashed Toolkit cover it? If so, what output from the Toolkit is useful in creating a finding aid for a web archive collection? Is there more that can be done? If so what?
I’d love to hear from you in our Slack (I’ve setup a channel #aut-finding-aid), or on GitHub if you’d like to create an issue.
An additional option outside the scope of the Archives Unleashed Toolkit, but closely related to it, is to index a web archive collection (all the ARC/WARC files) with UK Web Archive’s webarchive-discovery, and built a discovery interface around the Solr index with Warclight.
