Introduction
This is my third time collecting tweets for a Canadian Federal Election, and will most likely be last. The changes to the Twitter API including the Academic Research product track, twarc2, and great Documenting the Now Slack have considerbly lowered the barrier to collecting and analyizing Twitter data. I’m proud of the work I’ve done over the last seven years collecting and analyizing tweets. I hope it provided a solid implementation pattern for others to be build on in the future!
If you want to check out past Canadian election Twitter dataset analysis:
- An Open-Source Strategy for Documenting Events: The Case Study of the 42nd Canadian Federal Election on Twitter
- Exploring #elxn43 Twitter Data
In this analysis, I’m going to provide a mix of examples for examining the overall dataset; using twarc utilities, twut, and pandas. The format of this post is pretty much the same as the last election post I did, much like the results of this election!
Overview
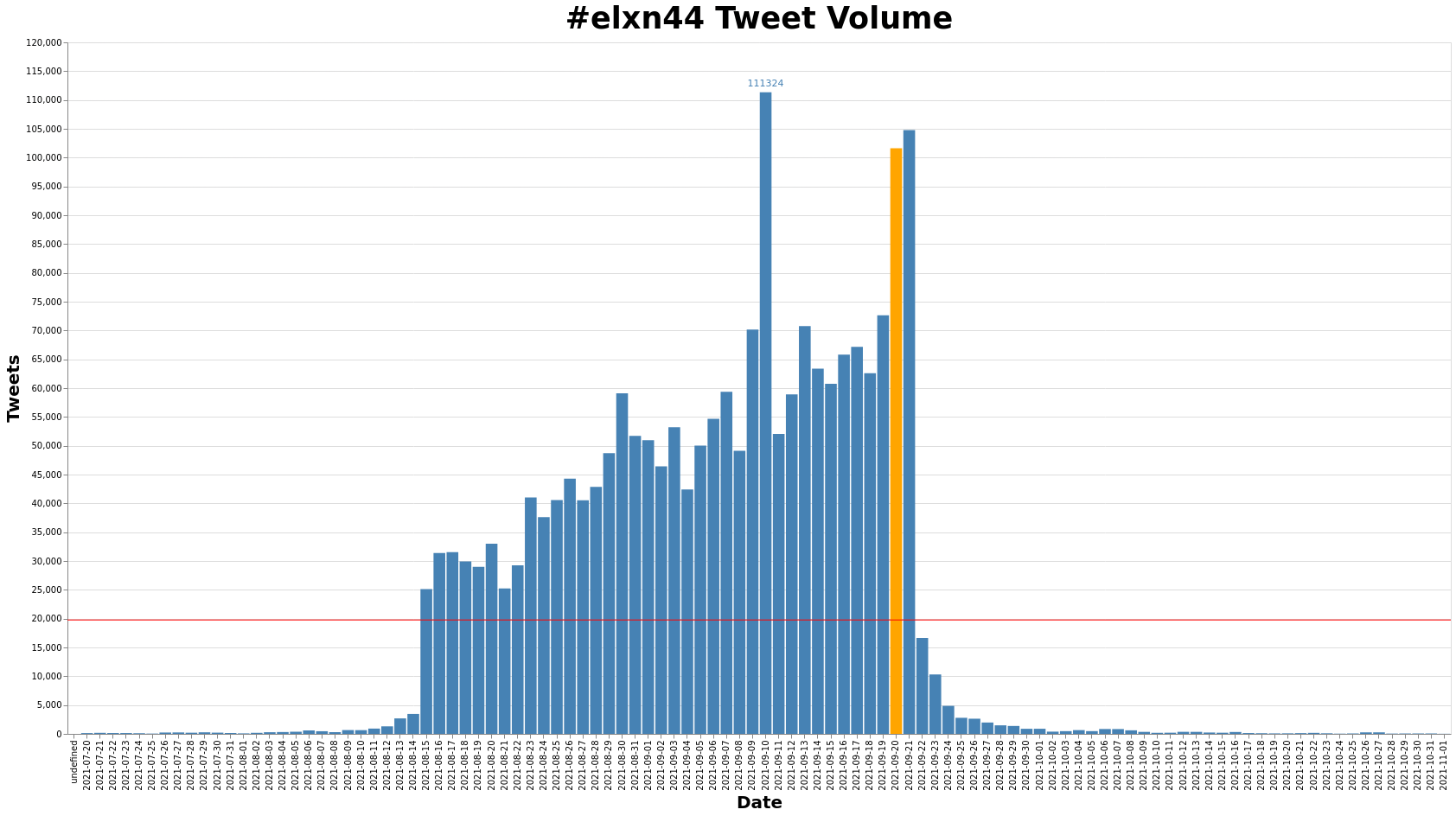
The dataset was collected with Documenting the Now’s twarc. It contains 2,075,645 tweet ids for #elxn44 tweets.
If you’d like to follow along, and work with the tweets, they can be “rehydrated” with Documenting the Now’s twarc, or Hydrator.
$ twarc hydrate elxn44-ids.txt > elxn44.jsonl
The dataset was created by collecting tweets from the the Standard Search API on a cron job every five days from July 28, 2021 - November 01, 2021.
Top languages
Using the full dataset and twut:
import io.archivesunleashed._
import spark.implicits._
val tweets = "elxn44_search.jsonl"
val tweetsDF = spark.read.json(tweets)
val languages = language(tweetsDF)
languages
.groupBy("lang")
.count()
.orderBy(col("count").desc)
.show(10)
+----+-------+
|lang| count|
+----+-------+
| en|1939944|
| fr| 72900|
| und| 56247|
| es| 2067|
| ht| 583|
| in| 417|
| tl| 373|
| ro| 286|
| ca| 256|
| pt| 245|
+----+-------+
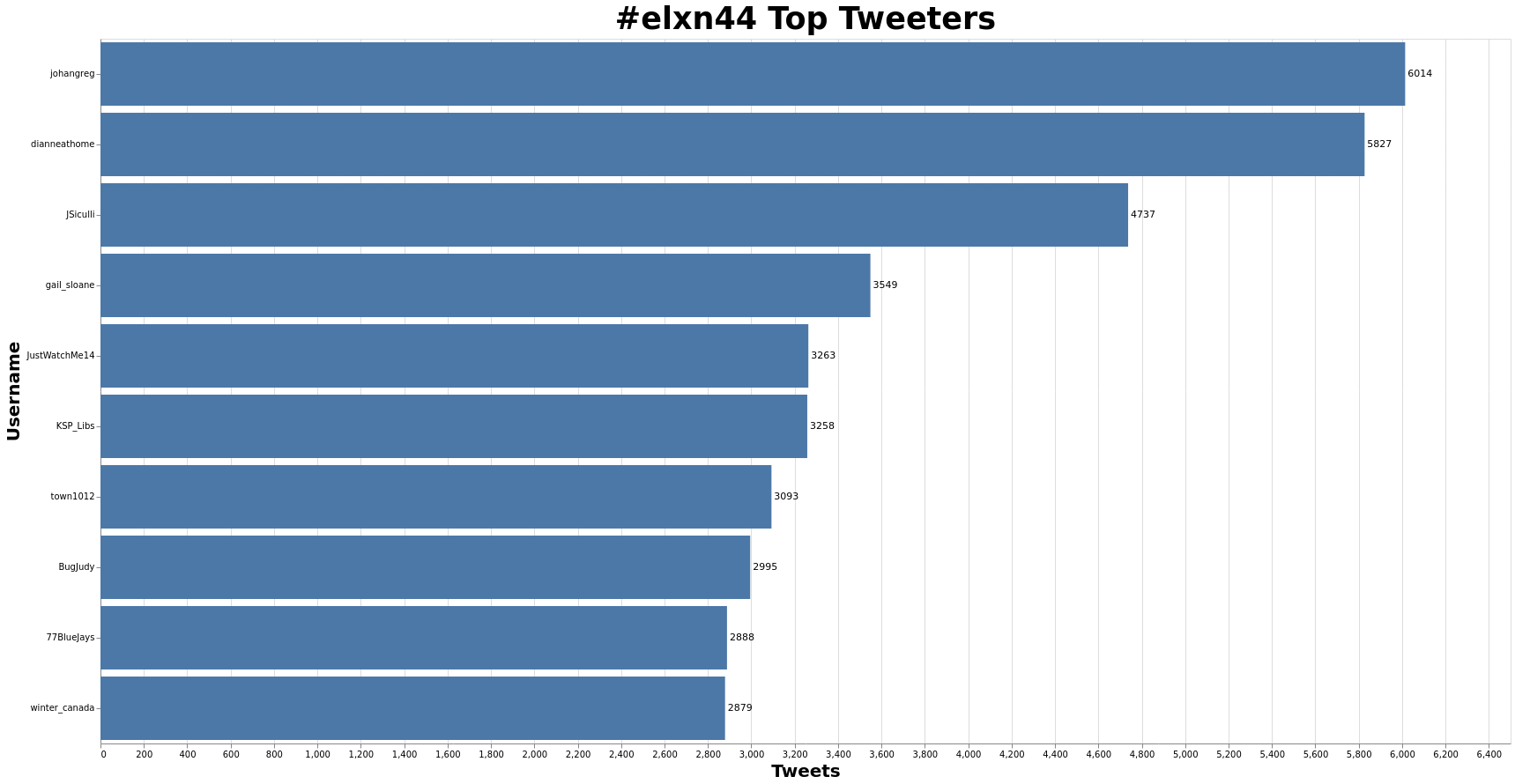
Top tweeters
Using the elxn44-user-info.csv derivative, and pandas:
import pandas as pd
import altair as alt
userInfo = pd.read_csv("elxn44-user-info.csv")
tweeters = userInfo['screen_name']
.value_counts()
.rename_axis("Username")
.reset_index(name="Count")
.head(10)
tweeter_chart = (
alt.Chart(tweeters)
.mark_bar()
.encode(
x=alt.X("Count:Q", axis=alt.Axis(title="Tweets")),
y=alt.Y("Username:O", sort="-x", axis=alt.Axis(title="Username")))
)
tweeter_values = tweeter_chart.mark_text(
align='left',
baseline='middle',
dx=3
).encode(
text='Count:Q'
)
Retweets
Using retweets.py from twarc utilities, we can find the most retweeted tweets:
$ python twarc/utils/retweets.py elxn44.jsonl | head
1438853428743184384,4930
1440147315390488584,3763
1433062401654472715,3645
1433484548034076700,2186
1436180477724041227,2033
1430717460035014657,1931
1427413115830890515,1813
1440157529737084928,1804
1434126903699456003,1540
1437456048663760896,1517
From there, we can use append the tweet ID to https://twitter.com/i/status/ to see the tweet. Here’s the top three:
4,930
Someone in Montréal is replacing photos of candidates with cats and I really don’t mind. #Elxn44 pic.twitter.com/eIPEcCPuDx
— Omar Burgan (@OhmsB) September 17, 20213,763
This election could have been an email.#Elxn44 #CanadaElection2021
— Ahmed Ali (@MrAhmednurAli) September 21, 20213,645
Anyone who has a responsibility to address this and does not is not fit to lead. Anyone who stands by and does nothing is complicit. Anyone who is surprised has not been paying attention. #cdnpoli #elxn44 #metoo https://t.co/qC0jM9ag96
— Jody Wilson-Raybould 王州迪 Vancouver Granville (@Puglaas) September 1, 2021
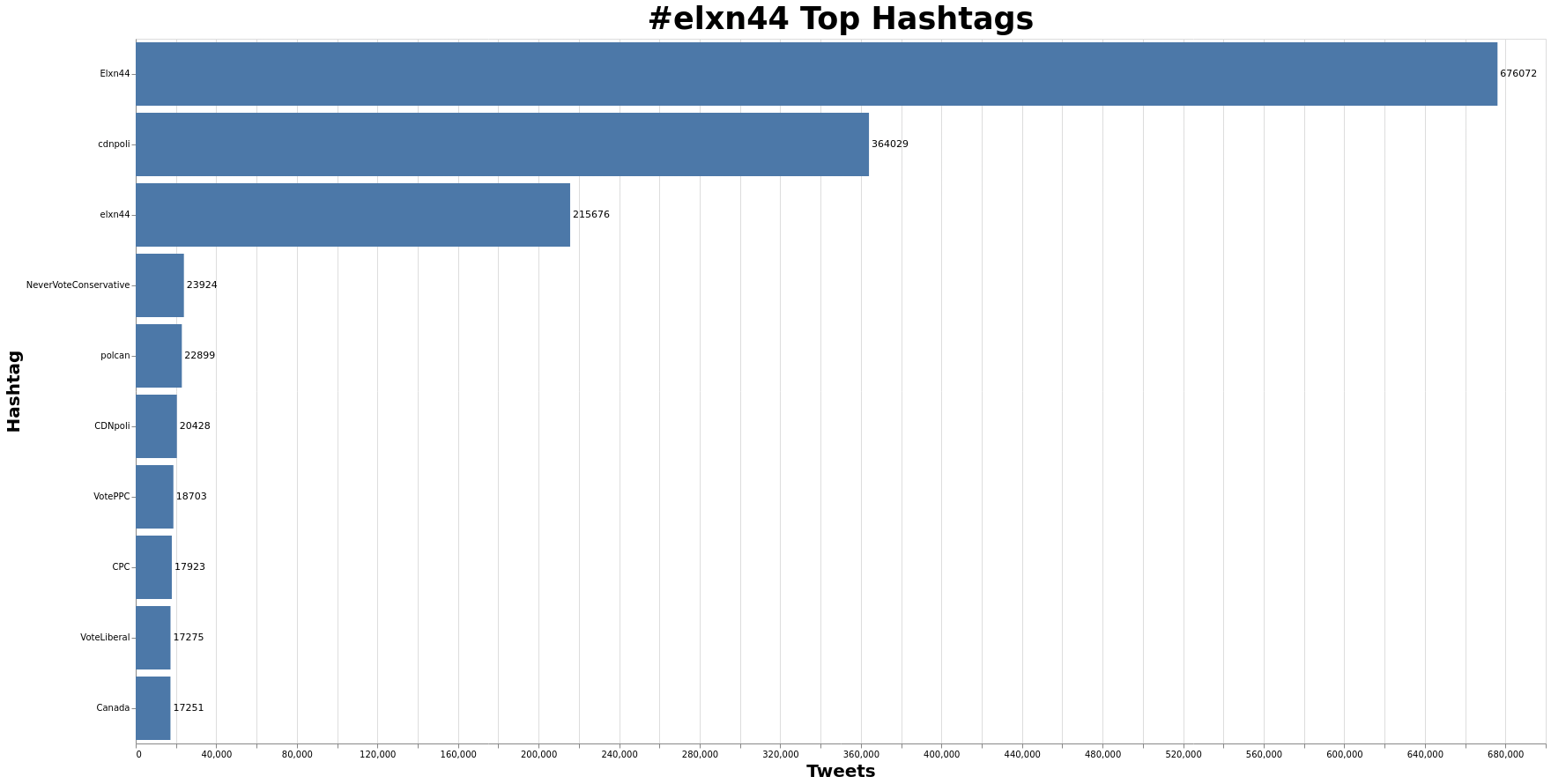
Top Hashtags
Using the elxn44-hashtags.csv derivative, and pandas:
hashtags = pd.read_csv("elxn44-hashtags.csv")
top_tags = hashtags.value_counts().rename_axis("Hashtags").reset_index(name="Count").head(10)
tags_chart = (
alt.Chart(top_tags)
.mark_bar()
.encode(
x=alt.X("Count:Q", axis=alt.Axis(title="Tweets")),
y=alt.Y("Hashtag:O", sort="-x", axis=alt.Axis(title="Hashtag")))
)
tags_values = tags_chart.mark_text(
align='left',
baseline='middle',
dx=3
).encode(
text='Count:Q'
)
(tags_chart + tags_values).configure_axis(titleFontSize=20).configure_title(fontSize=35, font='Courier').properties(height=800, width=1600, title="#elxn44 Top Hashtags")
Top URLs
Using the full dataset and twut:
import io.archivesunleashed._
import spark.implicits._
val tweets = "elxn44_search.jsonl"
val tweetsDF = spark.read.json(tweets)
val urlsDF = urls(tweetsDF)
urlsDF
.groupBy("url")
.count()
.orderBy(col("count").desc)
.show(10)
+-------------------------------------------------------------------------------------------------------------------------------+-----+
|url |count|
+-------------------------------------------------------------------------------------------------------------------------------+-----+
|https://www.theglobeandmail.com/politics/article-majority-of-federal-conservative-candidates-wont-disclose-covid-19/ |1107 |
|https://t.co/asEA19aPuX |1073 |
|https://torontosun.com/news/election-2021/its-what-we-have-to-do-liberal-candidate-says-housing-tax-is-coming |672 |
|https://t.co/PYcZuMEeWT |644 |
|https://montrealgazette.com/news/national/election-2021/survivors-of-dawson-college-shootings-urge-voters-to-shun-conservatives|491 |
|http://leadnow.ca/Cooperate2021 |472 |
|http://elections.ca |467 |
|https://www.theglobeandmail.com/politics/article-liberal-candidate-facing-15-million-lawsuit-over-pandemic-mask-making/ |453 |
|https://www.arcc-cdac.ca/erin-otoole-is-still-not-pro-choice/ |451 |
|http://Globalnews.ca |448 |
+-------------------------------------------------------------------------------------------------------------------------------+-----+
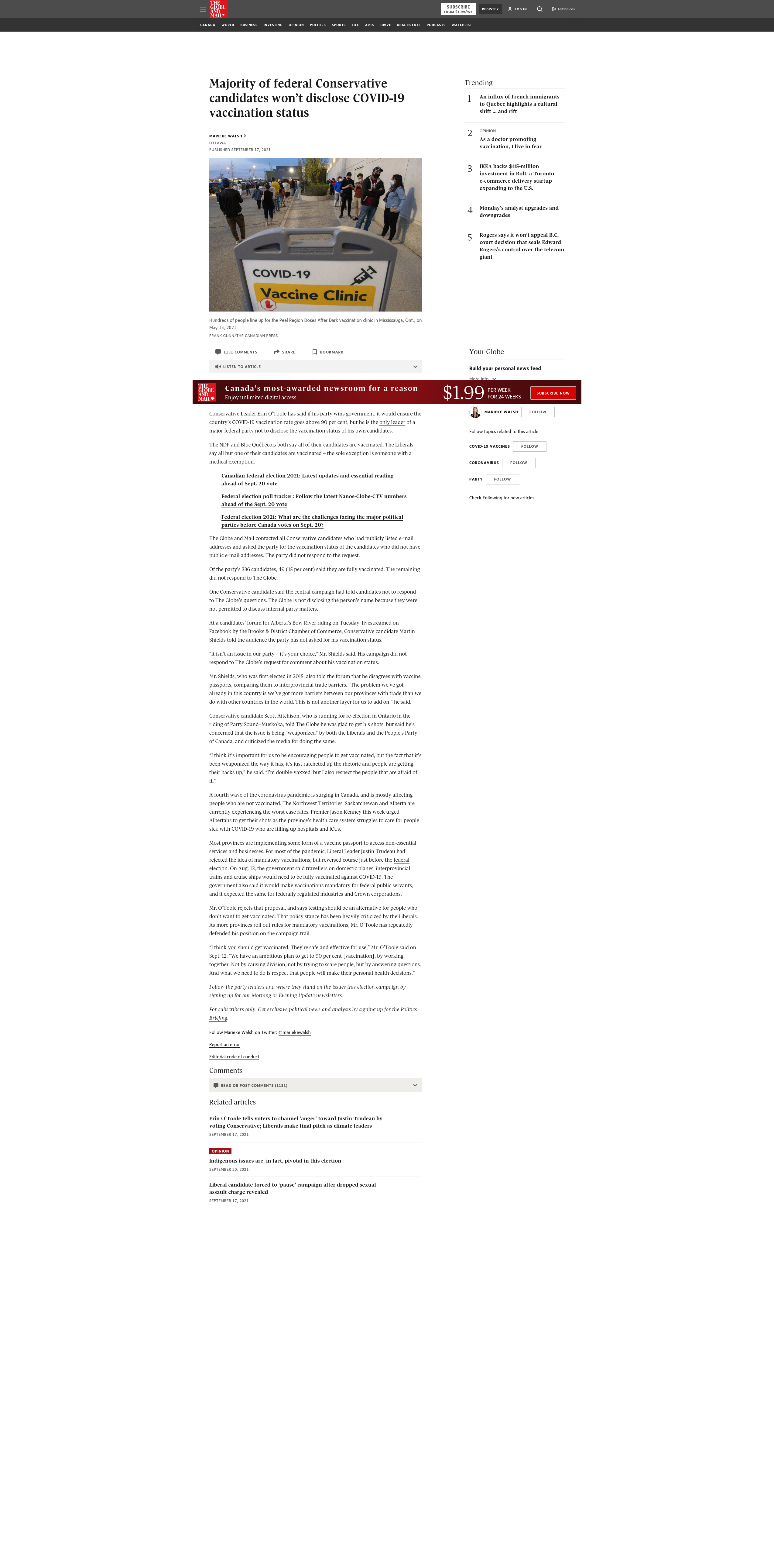
Adding URLs to Internet Archive
Do you know about the Internet Archive’s handy Save Page Now API?
Well, you could submit all those URLs to the Internet Archive if you wanted to.
You have be nice, and need to include a 5 second pause between each submission, otherwise your IP address will be blocked for 5 minutes!!
<h1>Too Many Requests</h1>
We are limiting the number of URLs you can submit to be Archived to the Wayback Machine, using the Save Page Now features, to no more than 15 per minute.
<p>If you submit more than that we will block Save Page Now requests from your IP number for 5 minutes.
</p>
<p>
Please feel free to write to us at info@archive.org if you have questions about this. Please include your IP address and any URLs in the email so we can provide you with better service.
</p>
You can use something like Raffaele Messuti’s example here.
Or, a one-liner if you prefer!
$ while read -r line; do curl -s -S "https://web.archive.org/save/$line" && echo "$line submitted to Internet Archive" && sleep 5; done < elxn44-urls.txt
I wonder what the delta is this time between collecting organizations, Internet Archive, and Tweeted URLs is?
Top media urls
Using the full dataset and twut:
import io.archivesunleashed._
import spark.implicits._
val tweets = "elxn44_search.jsonl"
val tweetsDF = spark.read.json(tweets)
val mediaUrlsDF = mediaUrls(tweetsDF)
mediaUrlsDF
.groupBy("image_url")
.count()
.orderBy(col("count").desc)
.show(10)
+----------------------------------------------------------------------------------------------------------+-----+
|image_url |count|
+----------------------------------------------------------------------------------------------------------+-----+
|https://pbs.twimg.com/media/E_fVjfpX0AIuzbk.jpg |4447 |
|https://pbs.twimg.com/media/E_x3pCIUYAEflui.jpg |1530 |
|https://pbs.twimg.com/media/E88AJEGXEAomOpF.jpg |1350 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/640x360/Tl3_CcAIuO1muNYb.mp4?tag=12 |1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/1280x720/hTx3MPjA_q4agA8B.mp4?tag=12 |1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/480x270/h0r1T_9vvycNfqbD.mp4?tag=12 |1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/pl/Jn2iGhdECjYPQUbD.m3u8?tag=12&container=fmp4|1009 |
|https://video.twimg.com/amplify_video/1428595346905600002/vid/480x270/8NUYCw9aDJTyRLVB.mp4?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428595346905600002/vid/1280x720/VbQB-q2htVF377Rn.mp4?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428595346905600002/pl/MS_CCvQ_RhXMI-jE.m3u8?tag=14 |908 |
+----------------------------------------------------------------------------------------------------------+-----+

Top video urls
Using the full dataset and twut:
import io.archivesunleashed._
import spark.implicits._
val tweets = "elxn44_search.jsonl"
val tweetsDF = spark.read.json(tweets)
val videoUrlsDF = videoUrls(tweetsDF)
videoUrlsDF
.groupBy("video_url")
.count()
.orderBy(col("count").desc)
.show(10)
+----------------------------------------------------------------------------------------------------------+-----+
|video_url |count|
+----------------------------------------------------------------------------------------------------------+-----+
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/1280x720/hTx3MPjA_q4agA8B.mp4?tag=12 |1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/480x270/h0r1T_9vvycNfqbD.mp4?tag=12 |1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/pl/Jn2iGhdECjYPQUbD.m3u8?tag=12&container=fmp4|1009 |
|https://video.twimg.com/ext_tw_video/1427709984591253516/pu/vid/640x360/Tl3_CcAIuO1muNYb.mp4?tag=12 |1009 |
|https://video.twimg.com/amplify_video/1428595346905600002/vid/640x360/fNG4AQPEDbK3iBkT.mp4?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428595346905600002/vid/480x270/8NUYCw9aDJTyRLVB.mp4?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428595346905600002/pl/MS_CCvQ_RhXMI-jE.m3u8?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428595346905600002/vid/1280x720/VbQB-q2htVF377Rn.mp4?tag=14 |908 |
|https://video.twimg.com/amplify_video/1428044986424070146/pl/0HqYKJ8inSozt6oK.m3u8?tag=14 |838 |
|https://video.twimg.com/amplify_video/1428044986424070146/vid/1280x720/dkzhncX0hp4U_pKe.mp4?tag=14 |838 |
+----------------------------------------------------------------------------------------------------------+-----+
Images
We looked a bit at the media URLs above. Since we have a list (elxn44-media-urls.txt) of all of the media URLs, we can download them and get a high level overview of the entire collection with a couple different utilities.
Similar to the one-liner above, we can download all the images like so:
$ while read -r line; do wget "line"; done < elxn44-media-urls.txt
You can speed up the process if you want with xargs or GNU Parallel.
$ cat elxn4-media-urls.txt | parallel --jobs 24 --gnu "wget '{}'"
Juxta
Juxta is a really great tool that was created by Toke Eskildsen. I’ve written about it in the past, so I won’t go into an overview of it here.
That said, I’ve created a created a collage of the 212,621 images in the dataset. Click the image below to check it out.
If you’ve already hydrated the dataset, you can skip part of the process that occurs in demo_twitter.sh by setting up a directory structure, and naming files accordingly.
Setup the directory structure. You’ll need to have elxn44-ids.txt at the root of it, and hydrated.json.gz in the elxn44_downloads directory you’ll create below.
$ mkdir elxn44 elxn44_downloads
$ cp elxn44.jsonl elxn44_downloads/hydrated.json
$ gzip elxn44_downloads/hydrated.json
Your setup should look like:
├── elxn44
├── elxn44_downloads
│ ├── hydrated.json.gz
├── elxn44-ids.txt
From there you can fire up Juxta and wait while it downloads all the images, and creates the collage. Depending on the number of cores you have, you can make use of multiple threads by setting the THREADS variable. For example: THREADS=20.
$ THREADS=20 /path/to/juxta/demo_twitter.sh elxn44-ids.txt elxn44
Understanding the collage; you can follow along in the image chronologically. The top left corner of the image will be the earliest images in the dataset (July 28, 2021), and the bottom right corner will be the most recent images in the dataset (October 6 , 2021). Zoom in and pan around! The images will link back to the Tweet that they came from.
-30-
