Originally posted here.
Web archives are hard to use, and while the past activities of Archives Unleashed has helped to lower these barriers, they’re still there. But what if we could process our collections, place the derivatives in a data repository, and then allow our users to directly work with them in a cloud-hosted notebook? 🤔
Last year around this time, the Archives Unleashed team was working on what can now be referred to as our first iteration of notebooks for web archive analysis. This initial set of notebooks used the derivatives created by the Archives Unleashed Cloud, and made use of a “Madlibs” approach of tweaking variables to work through analysis of a given web archive collection. The team wrote this up, and presented a poster on it at JCDL 2019, “The Archives Unleashed Notebook: Madlibs for Jumpstarting Scholarly Exploration of Web Archives.” We also deployed a variation of them for the D.C. Datathon in the Spring of 2019. They were successful in helping teams jump start their research at the datathon. But looking back, I can see they were a challenge to use. Just look at this “Getting Started” section of the README.
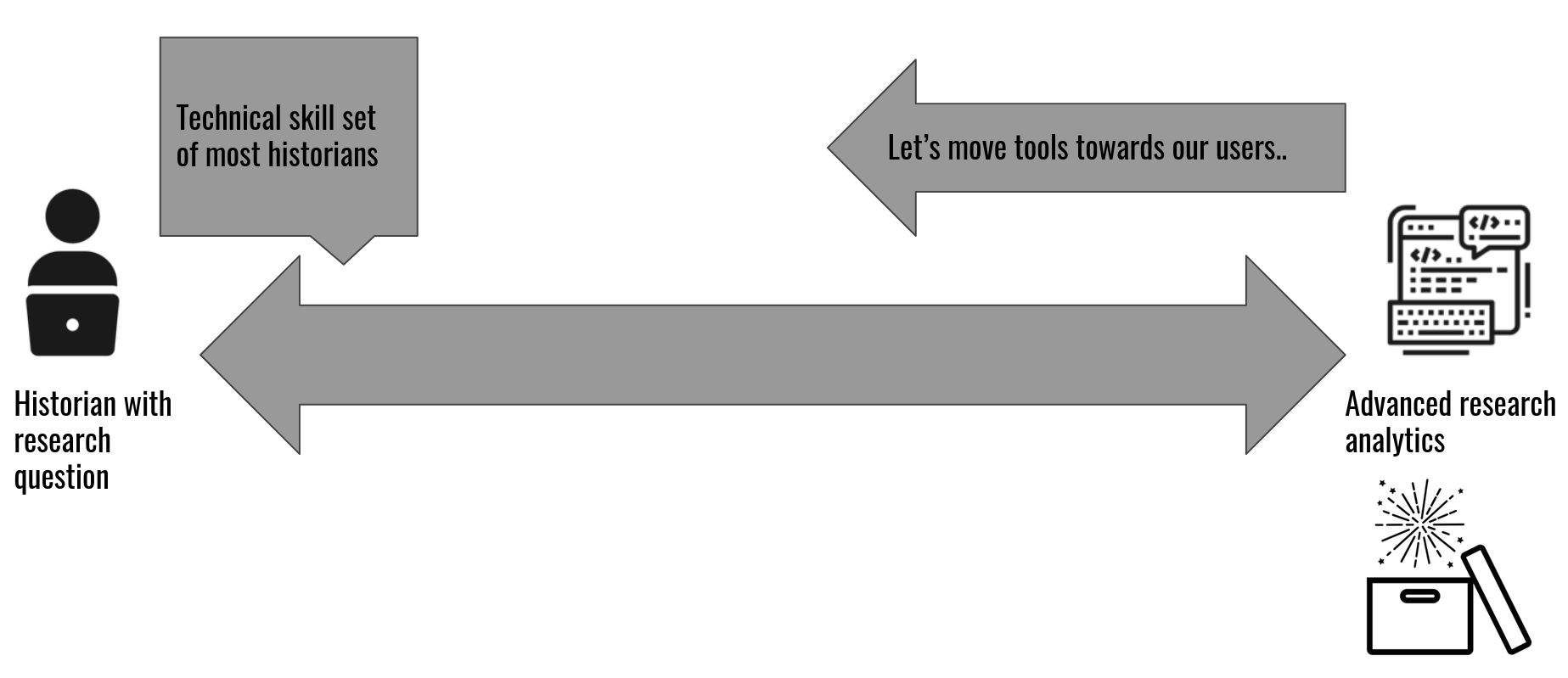
One of the biggest lessons that I keep relearning is that I need to make the tools I help create easier for the user. Our users come from a wide variety of backgrounds, and if we want to hit our goal of making “petabytes of historical internet content accessible to scholars and others interested in researching the recent past,” we must iterate on our tools and processes to make them easier and simpler to use so that web archives can be easily used as source material or data across a wide variety of academic disciplines. Looking back at the slides from a presentation Ian Milligan and I gave at RESAW 2019 the graphic Ian used in one of the slides really hits home for me.
Right now, a couple parts of the Archives Unleashed Project are culminating as we approach the final two datathons in New York and Montreal that, I hope, should move us a lot closer to a large segment of our users: a new release of the Archives Unleashed Toolkit, and an updated method for producing datasets for the datathons.
Earlier this month, we released version 0.50.0 of the Archives Unleashed Toolkit. If you check out the release notes, you’ll notice a lot of new functionality with DataFrames, and a new approach to our user documentation. We provide a “cookbook” approach to working with the Toolkit where we provide a number of examples of how to generate categories of results, and what to do with those results. Though, as much time and effort as we have put into improving the Toolkit over the last few years, there is only a small portion of our users who will jump into using it as is; a library for Apache Spark. Because it is a library for Apache Spark, it presents a large challenge to many of our users, and potential users. You need Java, Apache Spark, you need to know how you want to deploy Apache Spark, and will also need, potentially, above average command line skills to just get up and running with processing and analyzing web archive collections.
Over the past few years, we’ve not only iterated on our various software tools, we’ve also continuously tweaked our datathons. Since the attendees have just under two days to form teams, formulate research questions, and investigate the web archive collections, we’ve experimented with kick starting the analysis for participants. For earlier datathons, attendees were provided with some homework that provided them with a crash course in the Toolkit, and then we provided teams with some raw collections — just the WARCs! — and let them go to town. The datathons have evolved quite a bit since, we started with providing teams with Cloud derivatives along with the raw collection data, and most recently, we provided teams with raw collection data, derivatives and notebooks.
For our final two datathons coming up this spring, we decided to try one last iteration on the datasets and utilities we provide to attendees. We’re collaborating closely with our host institutions to not only provide access to the raw collection data of a few of their collections, but also process their web archives. We’re producing our standard set of Cloud derivatives as we have before, and we’re introducing some new derivatives that are DataFrame equivalents of the Cloud derivatives, as well as some new derivatives. These DataFrame derivatives are written out in the Apache Parquet format, which is a columnar storage format. These derivatives can be easily loaded in notebook using common data science tools and utilities, such as pandas, that we hope more users may already be familiar with.
So, how does this all work?
Collaborating with our great hosts at Columbia University (Columbia University Libraries, and Ivy Plus Libraries Confederation) for our New York datathon, and Bibliothèque et Archives nationales du Québec and the International Internet Preservation Consortium for our Montreal datathon, we’re almost done processing all of their collections. We’re providing access to the collection derivatives in Zenodo and Scholars Portal Dataverse. Each collection’s derivatives now has a citable DOI, and Zenodo supports DOI versioning. So, as a web archive collection grows, never versions of the derivatives can added to the record, allowing each version to have a DOI, as well as a DOI for the entire dataset. So, we can now start to see these web archive collections as data! An important note with these datasets, is that they are truly a collaboration, and you may notice the multiple authors on each. Each collection’s selectors, curators, and web archivists are co-authors, along with Archives Unleashed team members who processed the data.
So now that we have lots of web archive collection data, how can we improve the notebooks?
The answer here is to take what we learned in our previous notebooks, and throw pretty much everything else out and start from scratch. Why? If the end goal is to move closer to our users, then what if our users didn’t have to install Anaconda and all the dependencies locally to just fire up a notebook? What if they could just open a browser, and go from there? That’d be great, right? And, we can do that out of the box with Google Colaboratory! For free, you get up to 35G of RAM, ~100G of disk space, and a few CPU cores.
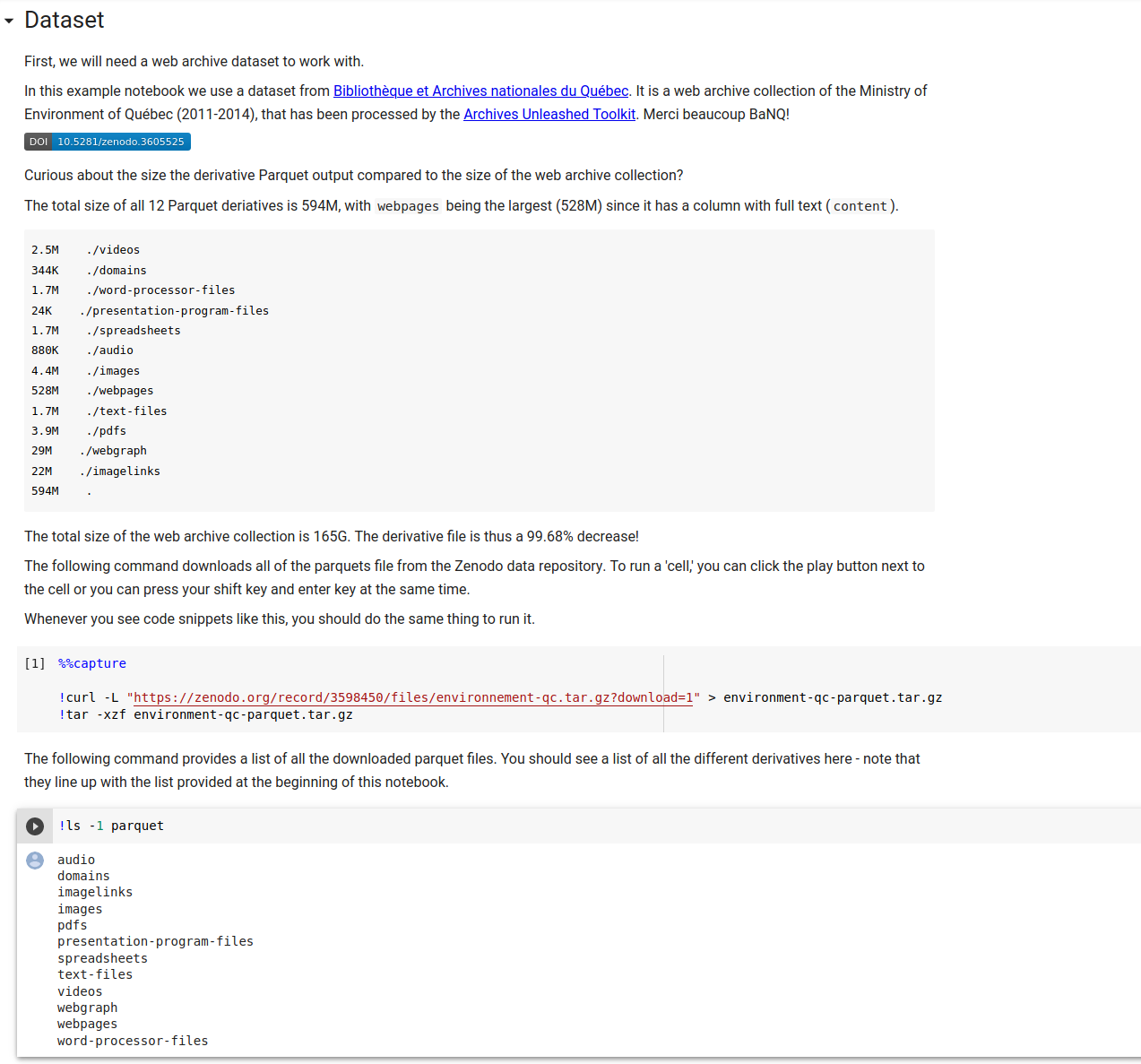
Let’s take a moment here to quickly walk through an example web archive collection as data, in a fairly simple notebook. Above, we see a brief description of the collection, and acknowledgement to Bibliothèque et Archives nationales du Québec (Merci beaucoup BAnQ!), and then we pull down the dataset to our Google Colabatory environment to work with.
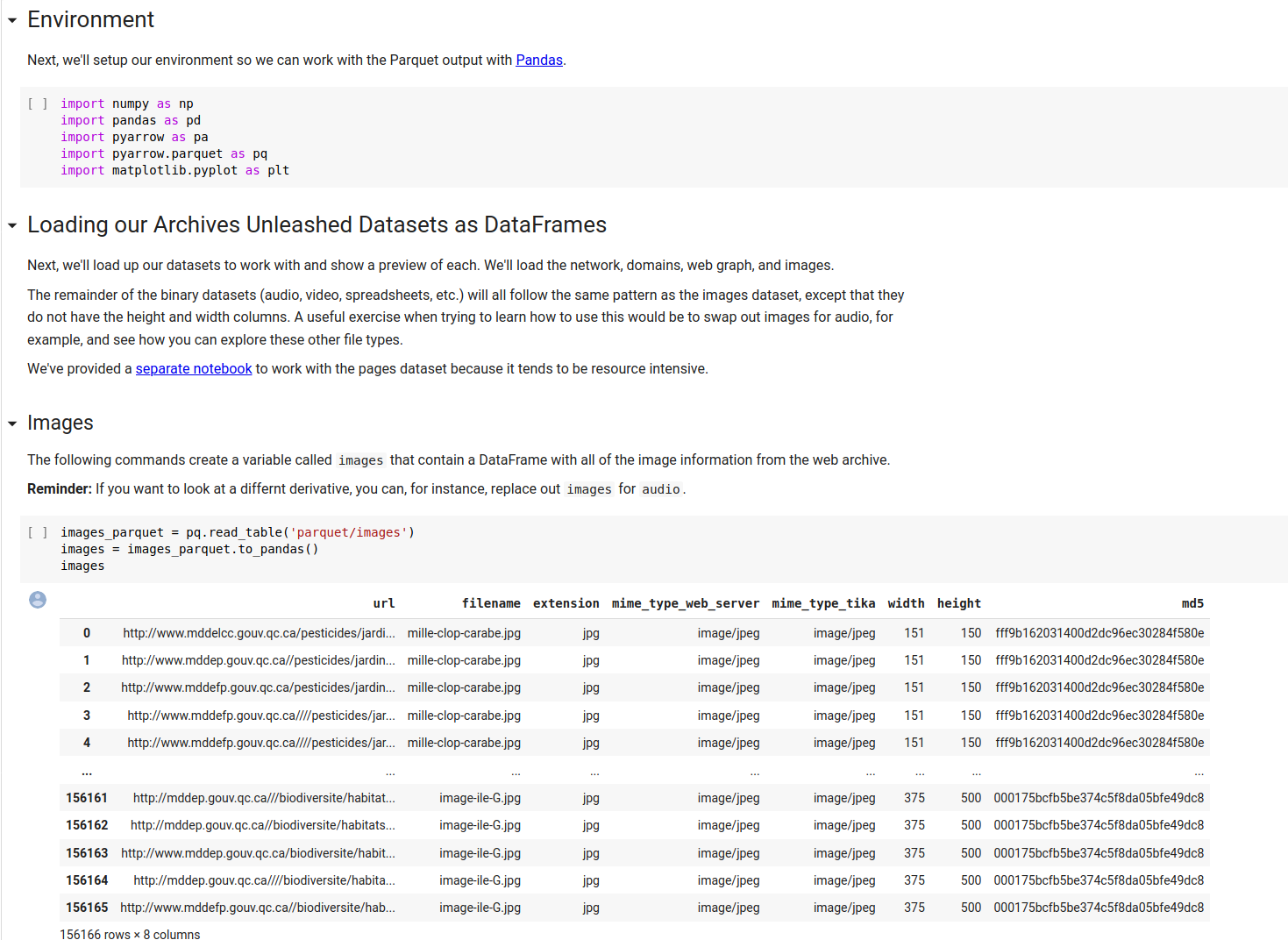
From there, we can load in some standard Python data science libraries, then load our Parquet derivatives as pandas DataFrames, and we’re off to the races. We don’t need the Toolkit at all!
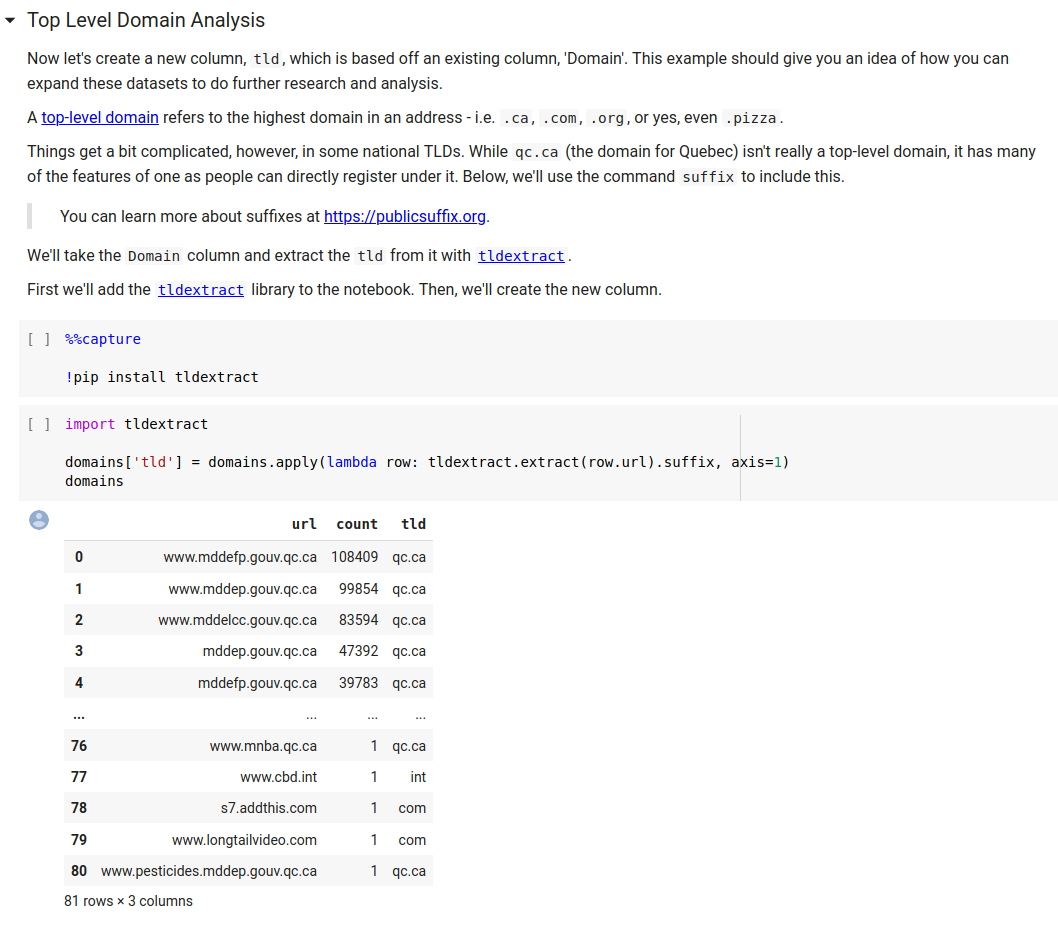
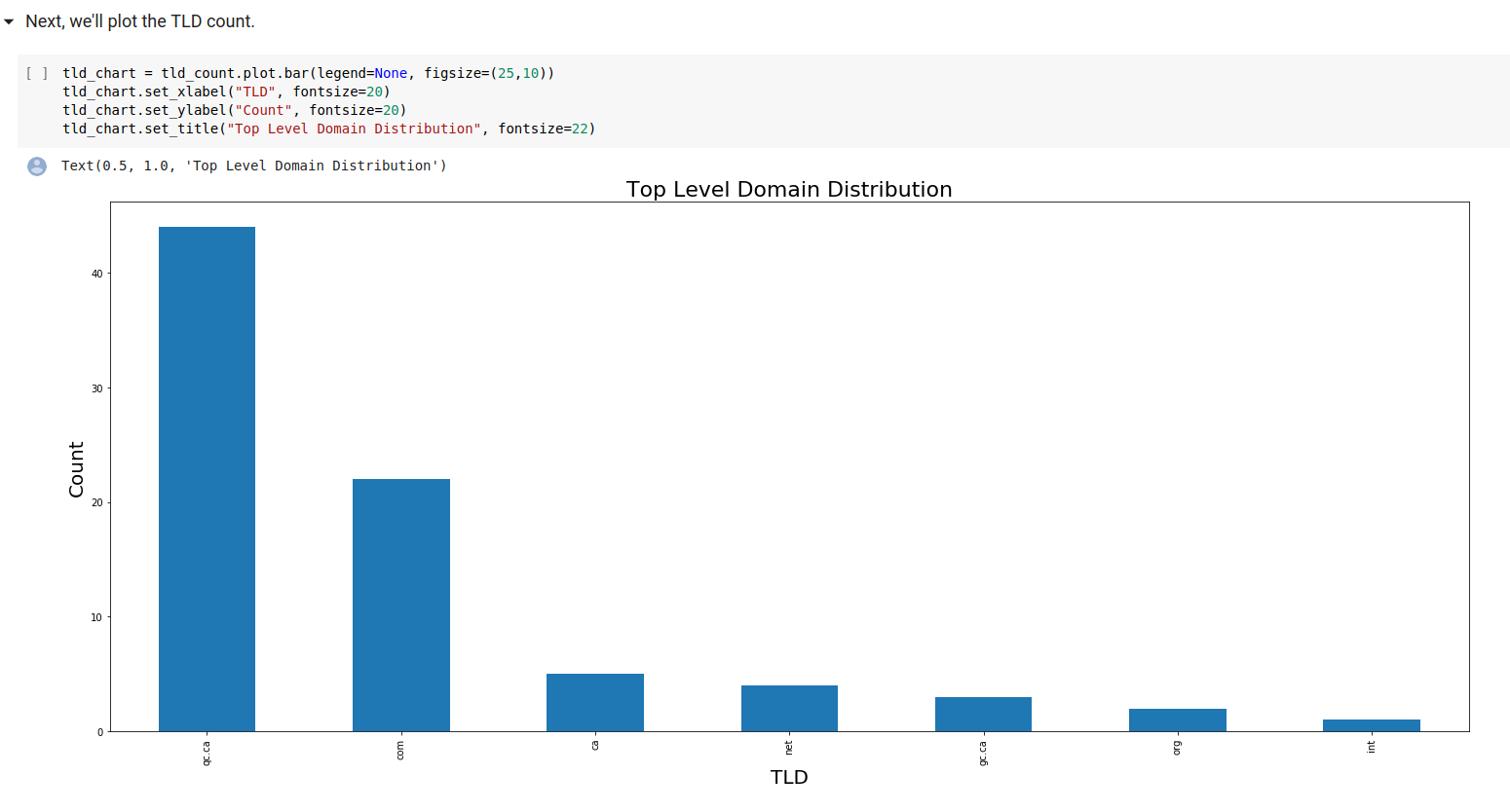
Above we can see that we pull in a handy library, tldextract, that allows us to examine the top occurring domains and suffixes, which in the next step plots them!
We have a few more example notebooks in the repository, and hope to add more in the future that are not only created by the Archives Unleashed team, but from users! That’d be pretty great, eh?
Is this the best we can do? Definitely not. There will hopefully be more improvements in the future. But, for the time being, we are getting there. I believe it is a huge improvement from where we started in July of 2017 in terms working with web archive collections. We’re helping to lower the barrier to access web archives by creating derivatives files, depositing them into data repositories so that those collections can truly be used as citable data, and we’re also providing a gentle on-ramp to analysis with our example notebooks.
The next items to work on and solve are further lowing the barriers to access web archive collections. The librarian and archivist in me wants to make sure we’re not gatekeepers, and see these really wonderful collections used. The researcher in me wants to get at this data for research with the least amount of interaction and friction possible.
So, what if there was a pipeline for processing a given collection, or segment of a collection, and publishing the derivatives in a given data repository along with a sample notebook?
🤔🤔🤔
I really think we could make this happen one day.
