On November 13, 2015 I was at the “Web Archives 2015: Capture, Curate, Analyze” listening to Ian Milligan give the closing keynote when Thomas Padilla tweeted the following to me:
@ruebot terrible news, possible charlie hebdo connection - https://t.co/SkEusgqgz5
— Thomas Padilla (@thomasgpadilla) November 13, 2015I immediately started collecting.
When tragedies like this happen, I feel pretty powerless. But, I figure if I can collect something like this, similar to what I did for the Charlie Hebdo attacks, it’s something. Maybe these datasets can be used for something positive that happened out of all this negative.
When I started collecting, it just so happened that the creator of twarc, Ed Summers, was sitting next to me, and he mentioned some new functionality that was part of the v0.4.0 release of twarc; Added --warnings flag to log warnings from the Twitter API about dropped tweets during streaming.
What’s that mean? Basically, the public Stream API will not stream more the 1% of the total Twitter stream. If you are trying to capture something from the streaming API that exceeds 1% of the total Twitter stream, like for instance a hashtag or two related to a terrorist attack, the streaming API will drop tweets, and notify that it has done so. There is a really interesting look at this by Kevin Driscoll, Shawn Walker in the International Journal of Communication.
Ed fired up the new version of twarc and began streaming as well so we could see what was happening. We noticed that we were getting warnings of around 400 dropped tweets every request (seconds), then it quickly escalated up to over 28k dropped tweets every request. What were were trying to collect was over 1% of the total Twitter stream.
Dataset
Collection started on November 13, 2015 using both the streaming and search API. This is what it looked like:
$ twarc.py --search "#paris OR #Bataclan OR #parisattacks OR #porteouverte" > paris-search.json
$ twarc.py --stream "#paris,#Bataclan,#parisattacks,#porteouverte" > paris-stream.json
I took the strategy of utilizing both the search and streaming API for collection due to what was noted above about hitting the 1% of the total Twitter stream limit. The idea was that if I’m hitting the limit with stream, theoretically I should be able to capture any tweets that were dropped with the search API. The stream API collection ran continuously during the collection period from November 13, 2015 to December 11, 2015. The search API collection was run, then once finished, immediately started back up over the collection period. During the first two weeks of collection, the search API collection would take about a week to finish. In recollection, I should have made note of the exact times it took to collect to get some more numbers to look at. That said, I’m not confident I was able to grab every tweet related to the hashtags I was collecting on. The only way, I think, I can be confident is by comparing this dataset with a dataset from Gnip. But, I am confident that I have a large amount of what was tweeted.
Once I finished collecting, I combined the json files, and deduplicated with deduplicate.py, and then created a list of tweet ids with ids.py.
If you want to follow along or do your own analysis with the dataset, you can “hydrate” the dataset with twarc. You can grab the Tweet ids for the dataset from here (Data & Analysis tab).
$ twarc.py --hydrate paris-tweet-ids.txt > paris-tweets.json
The hydration process will take some time; 72,000 tweets/hour. You might want to use something along the lines of GNU Screen, tmux, or nohup since it’ll take about 207.49 hours to completely hydrate.
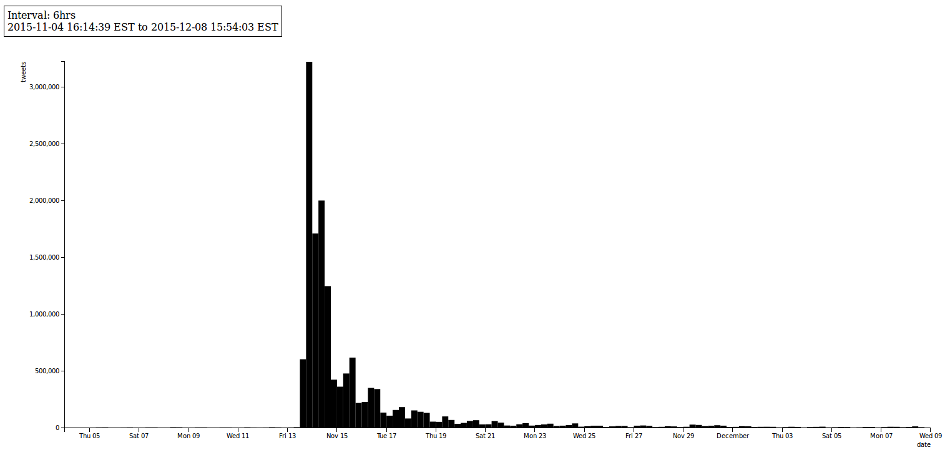
created with Peter Binkley’s twarc-report
Overview
I’m only going to do a quick analysis of the dataset here since I want to get the dataset out, and allow others to work with it. Tweets with geocoordinates is not covered below, but you can check out a map of tweets here.
There are a number of friendly utilities that come with twarc that allow for a quick exploratory analysis of a given collection. In addition, Peter Binkley’s twarc-repot is pretty handy for providing a quick overview of a given dataset.
Users
We are able to create a list of the unique Twitter username names in the dataset by using users.py, and additionally sort them by the number of tweets:
$ python ~/git/twarc/utils/users.py paris-valid-deduplicated.json > paris-users.txt$ cat paris-users.txt | sort | uniq -c | sort -n > paris-users-unique-sorted-count.txt$ cat paris-users-unique-sorted-count.txt | wc -l$ tail paris-users-unique-sorted-count.txt
From the above, we can see that there are 4,636,584 unique users in the dataset, and the top 10 accounts were as follows:
| 1. | 38,883 tweets | RelaxInParis |
| 2. | 36,504 tweets | FrancePeace |
| 3. | 12,697 tweets | FollowParisNews |
| 4. | 12,656 tweets | Reduction_Paris |
| 5. | 10,044 tweets | CNNsWorld |
| 6. | 8,208 tweets | parisevent |
| 7. | 7.296 tweets | TheMalyck_ |
| 8. | 6,654 tweets | genx_hrd |
| 9. | 6,370 tweets | DHEdomains |
| 10. | 4,498 tweets | paris_attack |
Retweets
We are able to create a lit of the most retweeted tweets in the dataset by using retweets.py:
$ python ~/git/twarc/utils/retweets.py paris-valid-deduplicated.json > paris-retweets.json$ python ~/git/twarc/utils/tweet_urls.py paris-retweets.json > paris-retweets.txt
| 1. | 53,639 retweets | https://twitter.com/PNationale/status/665939383418273793 |
| 2. | 44,457 retweets | https://twitter.com/MarkRuffalo/status/665329805206900736 |
| 3. | 41,400 retweets | https://twitter.com/NiallOfficial/status/328827440157839361 |
| 4. | 39,140 retweets | https://twitter.com/oreoxzhel/status/665499107021066240 |
| 5. | 37,214 retweets | https://twitter.com/piersmorgan/status/665314980095356928 |
| 6. | 24,955 retweets | https://twitter.com/Fascinatingpics/status/665458581832077312 |
| 7. | 22,124 retweets | https://twitter.com/RGerrardActor/status/665325168953167873 |
| 8. | 22,113 retweets | https://twitter.com/HeralddeParis/status/665327408803741696 |
| 9. | 22,069 retweets | https://twitter.com/Gabriele_Corno/status/484640360120209408 |
| 10. | 21,401 retweets | https://twitter.com/SarahMatt97/status/665383304787529729 |
Hashtags
We were able to create a list of the unique tags using in our dataset by using tags.py.
$ python ~/git/twarc/utils/tags.py paris-valid-deduplicated.json > paris-hashtags.txt$ cat paris-hashtags.txt | wc -l$ head elxn42-tweet-tags.txt
From the above, we can see that there were 26,8974 unique hashtags were used. The top 10 hashtags used in the dataset were:
| 1. | 6,812,941 tweets | #parisattacks |
| 2. | 6,119,933 tweets | #paris |
| 3. | 1,100,809 tweets | #bataclan |
| 4. | 887,144 tweets | #porteouverte |
| 5. | 673,543 tweets | #prayforparis |
| 6. | 444,486 tweets | #rechercheparis |
| 7. | 427,999 tweets | #parís |
| 8. | 387,699 tweets | #france |
| 9. | 341,059 tweets | #fusillade |
| 10. | 303,410 tweets | #isis |
URLs
We are able to create a list of the unique URLs tweeted in our dataset by using urls.py, after first unshortening the urls with unshorten.py and unshrtn.
$ python ~/git/twarc/utils/urls.py paris-valid-deduplicated-unshortened.json > paris-tweets-urls.txt$ cat paris-tweets-urls.txt | sort | uniq -c | sort -n > paris-tweets-urls-uniq.txt$ cat paris-tweets-urls.txt | wc -l$ cat paris-tweets-urls-uniq.txt | wc -l$ tail paris-tweets-urls-uniq.txt
From the above, we can see that there were 5,561,037 URLs tweeted, representing 37.22% of total tweets, and 858,401 unique URLs tweeted. The top 10 URLs tweeted were as follows:
| 1. | 46,034 tweets | http://www.bbc.co.uk/news/live/world-europe-34815972?ns_mchannel=social&ns_campaign=bbc_breaking&ns_source=twitter&ns_linkname=news_central |
| 2. | 46,005 tweets | https://twitter.com/account/suspended |
| 3. | 37,509 tweets | http://www.lefigaro.fr/actualites/2015/11/13/01001-20151113LIVWWW00406-fusillade-paris-explosions-stade-de-france.php#xtor=AL-155- |
| 4. | 35,882 tweets | http://twibbon.com/support/prayforparis-2/twitter |
| 5. | 33,531 tweets | http://www.bbc.co.uk/news/live/world-europe-34815972 |
| 6. | 33,039 tweets | https://www.rt.com/news/321883-shooting-paris-dead-masked/ |
| 7. | 24,221 tweets | https://www.youtube.com/watch?v=-Uo6ZB0zrTQ |
| 8. | 23,536 tweets | http://www.bbc.co.uk/news/live/world-europe-34825270 |
| 9. | 21,237 tweets | https://amp.twimg.com/v/fc122aff-6ece-47a4-b34c-cafbd72ef386 |
| 10. | 21,107 tweets | http://live.reuters.com/Event/Paris_attacks_2?Page=0 |
Images
We are able to create a list of images tweeted in our dataset by using image_urls.py.
$ python ~/git/twarc/utils/image_urls.py paris-valid-deduplicated.json > paris-tweets-images.txt$ cat paris-tweets-images.txt | sort | uniq -c | sort -n > paris-tweets-images-uniq.txt$ cat paris-tweets-images-uniq.txt | wc -l$ tail paris-tweets-images-uniq.txt
From the above, we can see that there were 6,872,441 total images tweets, representing 46.00% of total tweets, and 660,470 unique images. The top 10 images tweeted were as follows:
- 49,051 Occurrences

- 43,348 Occurrences

- 22,615 Occurrences

- 21,325 Occurrences

- 20,689 Occurrences

- 19,696 Occurrences

- 19,597 Occurrences

- 19,096 Occurrences

- 16,772 Occurrences

- 15,364 Occurrences

