Twarc there it is!
Nick Ruest
York University
Data Love-In
Vancouver, Canada
February 14, 2018
Workshop Overview
Follow along!
Background
DocNow

Twitter APIs
Sample, Users, Followers, Friends, Trends, Timeline, Retweets, Replies
API Changes
Compat, Expanded
Stream
$ twarc filter "Vancouver" > vancouver.jsonl$ twarc filter --follow 255681367 > ian.jsonl$ twarc filter --locations "49.267132, -122.968941" > sfu.jsonlWhat's that 1% thing people talk about?


Search
18,000 tweets every 15 minutes
7 day window
$ twarc search "Vancouver" > vancouver.jsonl$ twarc search "to:ianmilligan1" > ian.jsonl$ twarc search --geocode "49.267132, -122.968941" > sfu.jsonlTwitter Data
It's just so wonderful to work with!

{
"contributors": null,
"truncated": true,
"text": "@realDonaldTrump's new #coverphoto. \n\nI mean... my God... the faces?!!? \n😠😠😠😠😠😠😠😠😠😠😠😠\n\n@CNN @JoshMalina… https://t.co/JUbyI5Foff",
"is_quote_status": false,
"in_reply_to_status_id": null,
"id": 898725869950074900,
"favorite_count": 0,
"entities": {
"symbols": [],
"user_mentions": [
{
"id": 25073877,
"indices": [
0,
16
],
"id_str": "25073877",
"screen_name": "realDonaldTrump",
"name": "Donald J. Trump"
},
{
"id": 759251,
"indices": [
87,
91
],
"id_str": "759251",
"screen_name": "CNN",
"name": "CNN"
},
{
"id": 24931027,
"indices": [
92,
103
],
"id_str": "24931027",
"screen_name": "JoshMalina",
"name": "🌎Joshua Malina🌎"
}
],
"hashtags": [
{
"indices": [
23,
34
],
"text": "coverphoto"
}
],
"urls": [
{
"url": "https://t.co/JUbyI5Foff",
"indices": [
105,
128
],
"expanded_url": "https://twitter.com/i/web/status/898725869950074880",
"display_url": "twitter.com/i/web/status/8…"
}
]
}
So, that's the gist of a tweet, what can we do with a bunch of those?

There are a lot of potential fields!
...if you're curious...
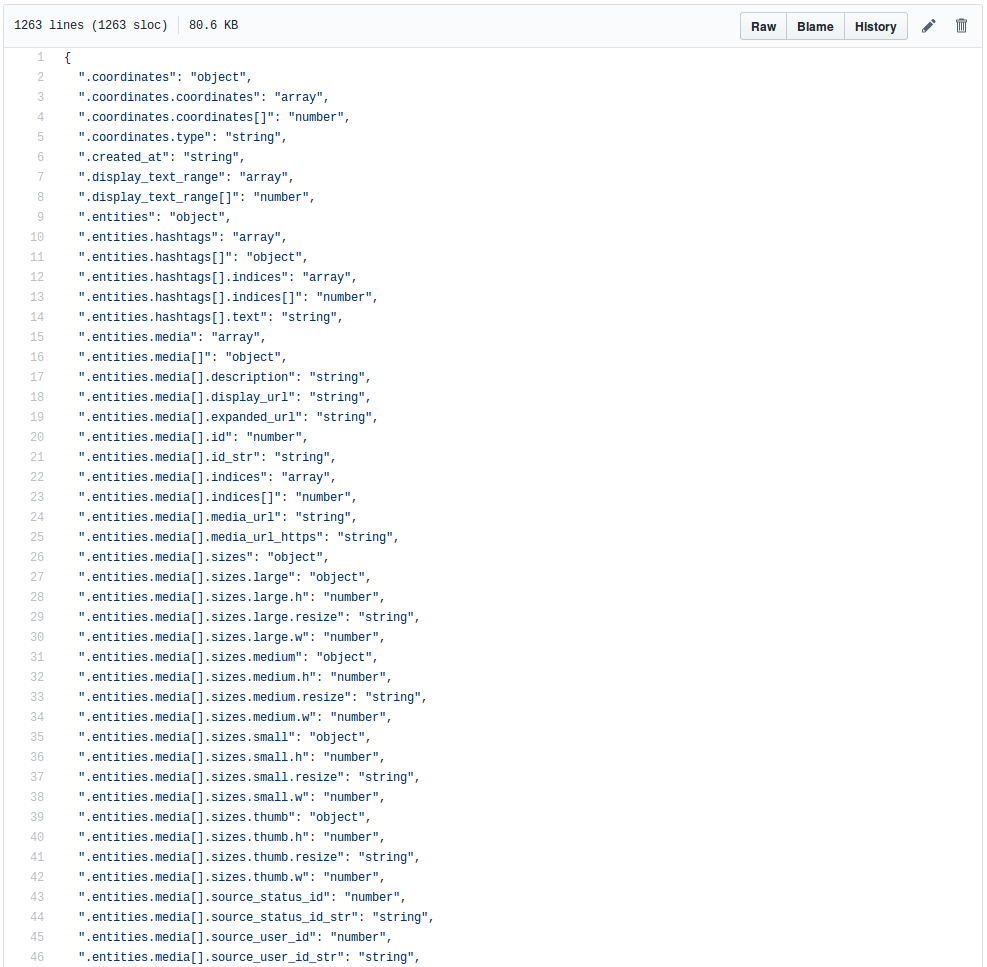
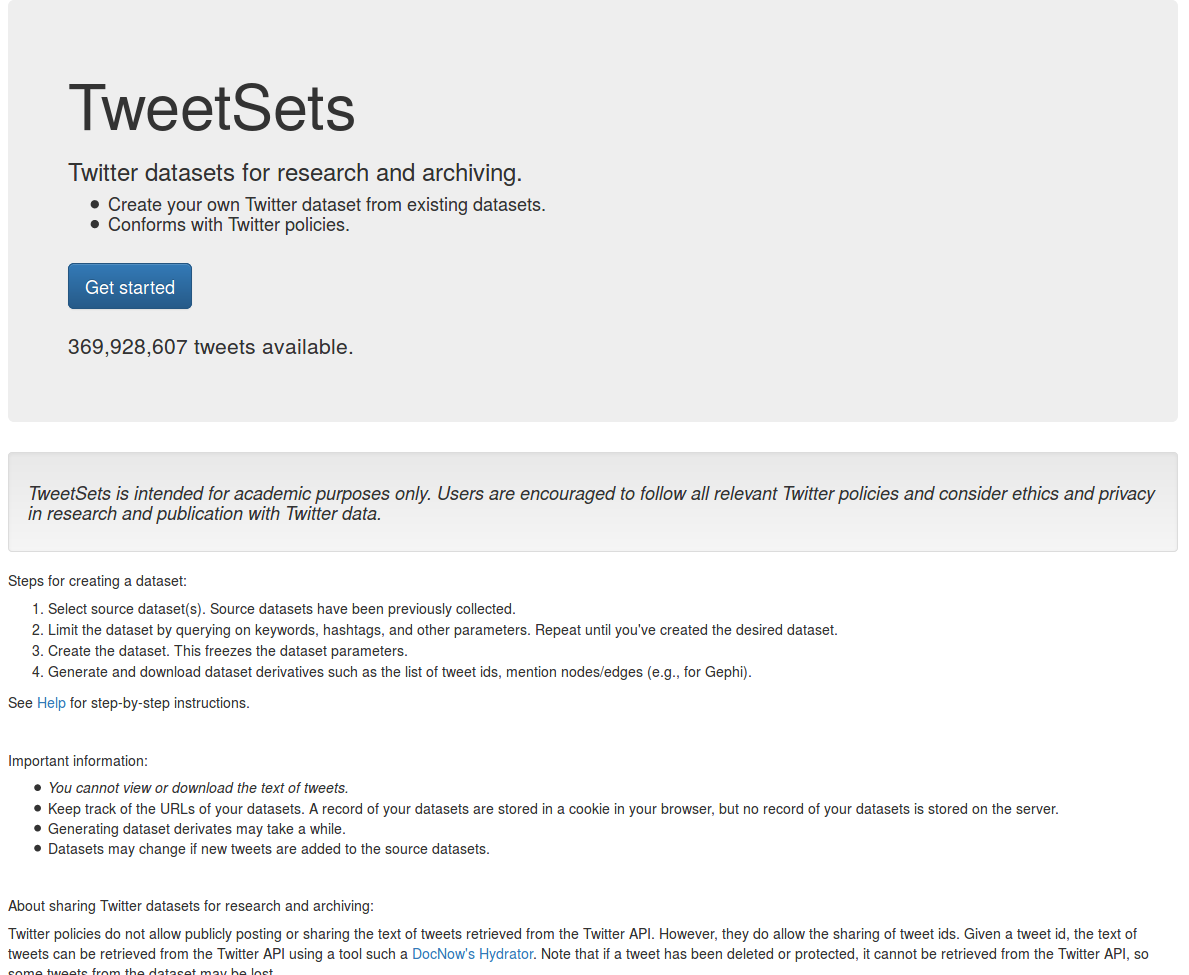
Derivative datasets
Tweet IDs
On Forgetting and hydration
Twitter ToS ✅
$ twarc dehydrate tweets.jsonl > tweet-ids.txt
Utilities
(We'll get more into these later!)
Extracting URLs
cat tweets.json | urls.py | sort | uniq > urls.txtBut, what about shortened URLs?
If I have all the shortened unique URLs...
That's a seed list!!
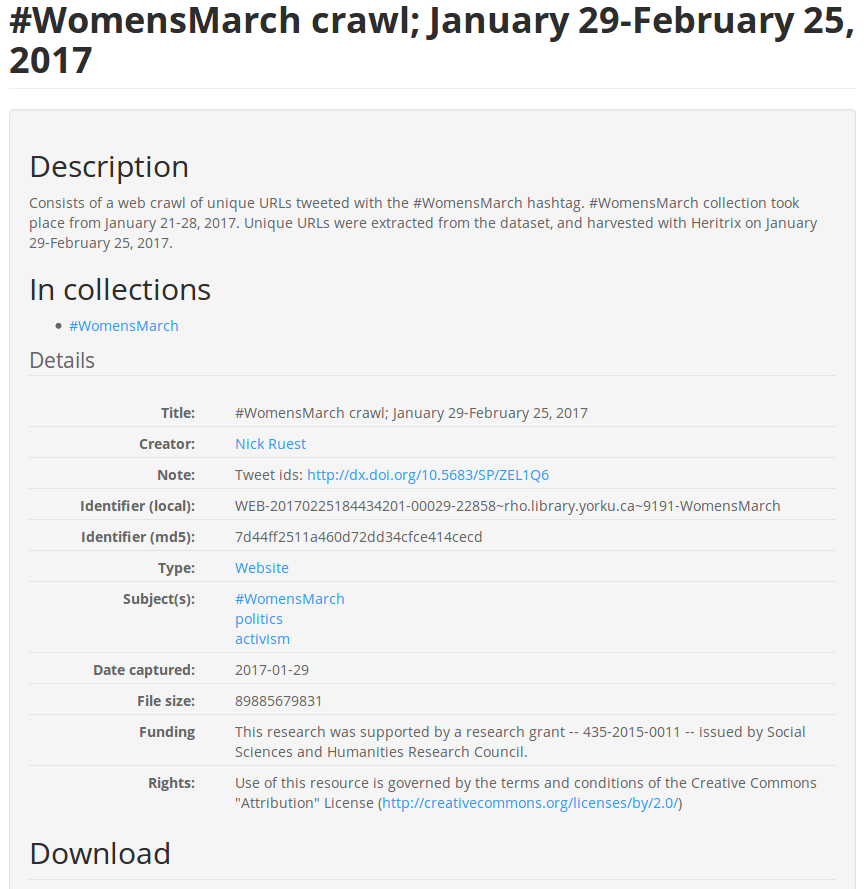
cat $URLS | while read line; do
curl -s -S "https://web.archive.org/save/$line" > /dev/null
sleep 1
done

People Tweet a lot of images...
$ cat tweets.json | images.py > image_urls.txt$ cat image_urls.txt | while read line; do wget $line; doneWhat does 1+ million images look like?



Requirements
Twitter Account
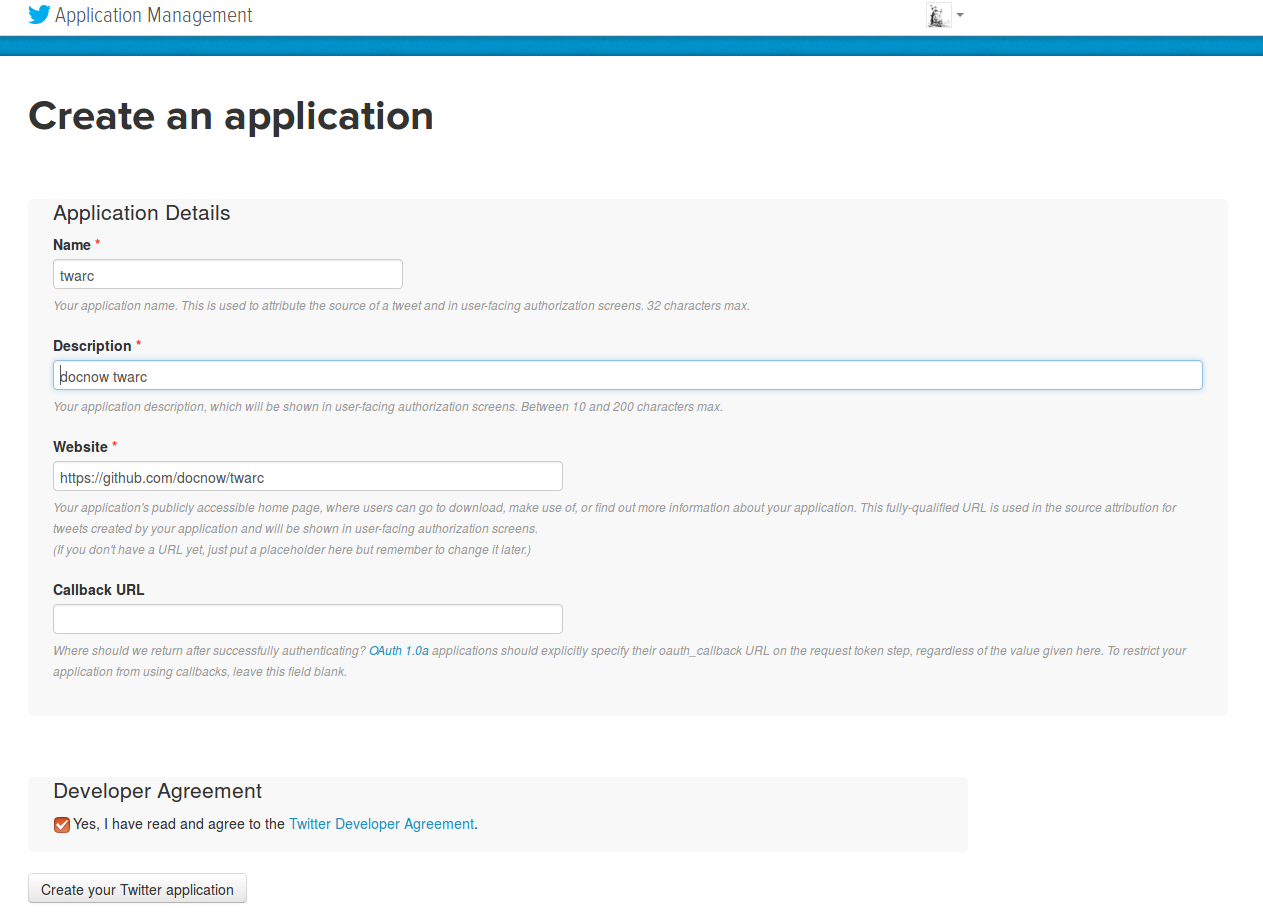
Assumptions
You already have Python on your system.
You hopefully have pip installed as well.
...if you don't
Nice to have

Install
$ sudo -H pip install twarc
$ sudo -H pip install twarc
Collecting twarc
Using cached twarc-1.3.4.tar.gz
Requirement already satisfied: pytest in /usr/local/lib/python3.5/dist-packages/pytest-3.2.1-py3.5.egg (from twarc)
Requirement already satisfied: python-dateutil in /usr/local/lib/python3.5/dist-packages (from twarc)
Requirement already satisfied: requests_oauthlib in /usr/local/lib/python3.5/dist-packages/requests_oauthlib-0.8.0-py3.5.egg (from twarc)
Requirement already satisfied: py>=1.4.33 in /usr/local/lib/python3.5/dist-packages/py-1.4.34-py3.5.egg (from pytest->twarc)
Requirement already satisfied: setuptools in /usr/local/lib/python3.5/dist-packages (from pytest->twarc)
Requirement already satisfied: six>=1.5 in /usr/lib/python3/dist-packages (from python-dateutil->twarc)
Requirement already satisfied: oauthlib>=0.6.2 in /usr/local/lib/python3.5/dist-packages (from requests_oauthlib->twarc)
Requirement already satisfied: requests>=2.0.0 in /usr/local/lib/python3.5/dist-packages (from requests_oauthlib->twarc)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.5/dist-packages (from requests>=2.0.0->requests_oauthlib->twarc)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.5/dist-packages (from requests>=2.0.0->requests_oauthlib->twarc)
Requirement already satisfied: idna<2.7,>=2.5 in /usr/local/lib/python3.5/dist-packages (from requests>=2.0.0->requests_oauthlib->twarc)
Requirement already satisfied: urllib3<1.23,>=1.21.1 in /usr/local/lib/python3.5/dist-packages (from requests>=2.0.0->requests_oauthlib->twarc)
Installing collected packages: twarc
Running setup.py install for twarc ... done
Successfully installed twarc-1.3.4
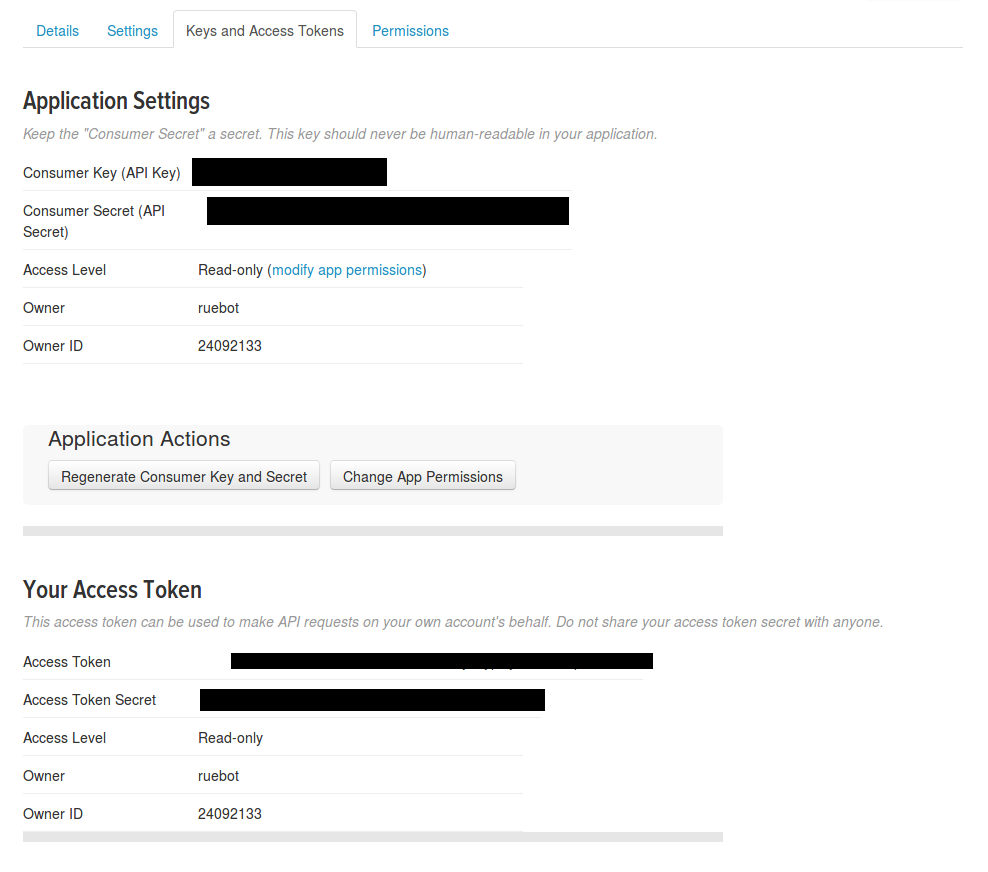
Let's configure twarc
$ twarc configure
$ twarc configure
Please enter Twitter authentication credentials.
consumer key: some key
consumer secret: some secret
access token: some access token
access token secret: some token secret
Let's create some datasets!
Option #1
Using the Sample API
Caveat: This can run a long time.
GNU Screen is your friend here.
$ twarc sample > sample_stream_tweets.jsonl
Check and see how things are going
In another terminal or tab
$ tail -f sample_stream_tweets.jsonl
$ tail -f sample_stream_tweets.jsonl
{"favorite_count": 0, "in_reply_to_user_id": null, "in_reply_to_status_id_str": null, "geo": null, "coordinates": null, "in_reply_to_screen_name": null, "id": 956541347850276865, "entities": {"hashtags": [], "symbols": [], "user_mentions": [], "urls": []}, "truncated": false, "text": "que bueno es cuando las marcas pagan la venida de un artista y las entradas andan regal\u00e1s. literalmente.", "in_reply_to_user_id_str": null, "is_quote_status": false, "timestamp_ms": "1516892203663", "reply_count": 0, "source": "Twitter Web Client", "lang": "es", "filter_level": "low", "created_at": "Thu Jan 25 14:56:43 +0000 2018", "user": {"listed_count": 54, "profile_link_color": "19CF86", "follow_request_sent": null, "default_profile_image": false, "verified": false, "profile_background_color": "FFFFFF", "protected": false, "profile_background_image_url": "http://abs.twimg.com/images/themes/theme1/bg.png", "notifications": null, "favourites_count": 32002, "id": 231650936, "profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme1/bg.png", "contributors_enabled": false, "created_at": "Wed Dec 29 03:13:34 +0000 2010", "profile_background_tile": false, "geo_enabled": true, "followers_count": 4014, "statuses_count": 134884, "following": null, "profile_image_url_https": "https://pbs.twimg.com/profile_images/937487532371206144/-0MAWyVf_normal.jpg", "url": "http://Instagram.com/gaptone", "profile_image_url": "http://pbs.twimg.com/profile_images/937487532371206144/-0MAWyVf_normal.jpg", "utc_offset": -10800, "name": "g.", "lang": "en", "screen_name": "gaptone", "is_translator": false, "friends_count": 530, "profile_banner_url": "https://pbs.twimg.com/profile_banners/231650936/1393422233", "location": "Pe\u00f1alol\u00e9n, Chile", "profile_text_color": "666666", "translator_type": "none", "description": "porque quiero, porque puedo y porque me toma.", "time_zone": "Santiago", "profile_use_background_image": false, "profile_sidebar_fill_color": "FFFFFF", "default_profile": false, "id_str": "231650936", "profile_sidebar_border_color": "FFFFFF"}, "retweeted": false, "retweet_count": 0, "id_str": "956541347850276865", "place": null, "in_reply_to_status_id": null, "favorited": false, "quote_count": 0, "contributors": null}
{"favorite_count": 0, "in_reply_to_user_id": null, "in_reply_to_status_id_str": null, "quoted_status_id": 955947308822204416, "coordinates": null, "in_reply_to_screen_name": null, "possibly_sensitive": false, "id": 956541347833331713, "entities": {"hashtags": [], "symbols": [], "user_mentions": [], "urls": [{"indices": [15, 38], "expanded_url": "https://twitter.com/ABC/status/955947308822204416", "display_url": "twitter.com/ABC/status/955\u2026", "url": "https://t.co/HG2RggK1FJ"}]}, "quoted_status_id_str": "955947308822204416", "truncated": false, "text": "Fuck Australia https://t.co/HG2RggK1FJ", "in_reply_to_user_id_str": null, "is_quote_status": true, "timestamp_ms": "1516892203659", "reply_count": 0, "display_text_range": [0, 14], "source": "Tweetlogix", "lang": "en", "filter_level": "low", "created_at": "Thu Jan 25 14:56:43 +0000 2018", "user": {"listed_count": 25, "profile_link_color": "990000", "follow_request_sent": null, "default_profile_image": false, "verified": false, "profile_background_color": "EBEBEB", "protected": false, "profile_background_image_url": "http://pbs.twimg.com/profile_background_images/547479838630506496/iWlT_Y-C.jpeg", "notifications": null, "favourites_count": 1933, "id": 165566903, "profile_background_image_url_https": "https://pbs.twimg.com/profile_background_images/547479838630506496/iWlT_Y-C.jpeg", "contributors_enabled": false, "created_at": "Sun Jul 11 23:40:26 +0000 2010", "profile_background_tile": true, "geo_enabled": true, "followers_count": 524, "statuses_count": 93462, "following": null, "profile_image_url_https": "https://pbs.twimg.com/profile_images/942326485628551168/CaAnXw9w_normal.jpg", "url": null, "profile_image_url": "http://pbs.twimg.com/profile_images/942326485628551168/CaAnXw9w_normal.jpg", "utc_offset": -28800, "name": "354", "lang": "en", "screen_name": "Ezell_Jenkins", "is_translator": false, "friends_count": 479, "profile_banner_url": "https://pbs.twimg.com/profile_banners/165566903/1419364032", "location": "LOST", "profile_text_color": "333333", "translator_type": "none", "description": "Staying black and minding my business...", "time_zone": "Pacific Time (US & Canada)", "profile_use_background_image": true, "profile_sidebar_fill_color": "F3F3F3", "default_profile": false, "id_str": "165566903", "profile_sidebar_border_color": "FFFFFF"}, "retweeted": false, "geo": null, "retweet_count": 0, "id_str": "956541347833331713", "place": null, "quoted_status": {"favorite_count": 1818, "in_reply_to_user_id": null, "in_reply_to_status_id_str": null, "geo": null, "coordinates": null, "in_reply_to_screen_name": null, "possibly_sensitive": false, "id": 955947308822204416, "entities": {"hashtags": [], "symbols": [], "user_mentions": [], "urls": [{"indices": [117, 140], "expanded_url": "https://twitter.com/i/web/status/955947308822204416", "display_url": "twitter.com/i/web/status/9\u2026", "url": "https://t.co/CY4lKmkS63"}]}, "truncated": true, "text": "YIKES: Horrifying video captures a spider wasp and a huntsman spider doing battle in the bathroom of a home in Aust\u2026 https://t.co/CY4lKmkS63", "in_reply_to_user_id_str": null, "is_quote_status": false, "reply_count": 716, "display_text_range": [0, 140], "source": "SocialFlow", "lang": "en", "filter_level": "low", "created_at": "Tue Jan 23 23:36:13 +0000 2018", "user": {"listed_count": 52185, "profile_link_color": "336699", "follow_request_sent": null, "default_profile_image": false, "verified": true, "profile_background_color": "6E8EB5", "protected": false, "profile_background_image_url": "http://pbs.twimg.com/profile_background_images/441965491024719872/pAv-lzCZ.jpeg", "notifications": null, "favourites_count": 462, "id": 28785486, "profile_background_image_url_https": "https://pbs.twimg.com/profile_background_images/441965491024719872/pAv-lzCZ.jpeg", "contributors_enabled": false, "created_at": "Sat Apr 04 12:40:32 +0000 2009", "profile_background_tile": false, "geo_enabled": true, "followers_count": 13362675, "statuses_count": 194187, "following": null, "profile_image_url_https": "https://pbs.twimg.com/profile_images/877547979363758080/ny06RNTT_normal.jpg", "url": "http://ABCNews.com", "profile_image_url": "http://pbs.twimg.com/profile_images/877547979363758080/ny06RNTT_normal.jpg", "utc_offset": -18000, "name": "ABC News", "lang": "en", "screen_name": "ABC", "is_translator": false, "friends_count": 734, "profile_banner_url": "https://pbs.twimg.com/profile_banners/28785486/1505493568", "location": "New York City / Worldwide", "profile_text_color": "333333", "translator_type": "regular", "description": "See the whole picture with @ABC News. Facebook: https://www.facebook.com/abcnews Instagram: https://www.instagram.com/abcnews", "time_zone": "Eastern Time (US & Canada)", "profile_use_background_image": true, "profile_sidebar_fill_color": "DDEEF6", "default_profile": false, "id_str": "28785486", "profile_sidebar_border_color": "FFFFFF"}, "retweeted": false, "extended_tweet": {"full_text": "YIKES: Horrifying video captures a spider wasp and a huntsman spider doing battle in the bathroom of a home in Australia. https://t.co/yWc8M74ueK https://t.co/dZAZr7TOHe", "display_text_range": [0, 145], "extended_entities": {"media": [{"sizes": {"medium": {"w": 720, "resize": "fit", "h": 720}, "thumb": {"w": 150, "resize": "crop", "h": 150}, "large": {"w": 720, "resize": "fit", "h": 720}, "small": {"w": 680, "resize": "fit", "h": 680}}, "type": "video", "media_url_https": "https://pbs.twimg.com/ext_tw_video_thumb/955947163317612546/pu/img/udGbjDJRKhE2w4ux.jpg", "video_info": {"variants": [{"bitrate": 256000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/240x240/HjU2fIlPjNSOwWWm.mp4"}, {"bitrate": 832000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/480x480/2Cj1P2M525Ohszg_.mp4"}, {"content_type": "application/x-mpegURL", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/pl/XH3mVSMfnL9JDdqZ.m3u8"}, {"bitrate": 1280000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/720x720/NcDTqJ8UUzaYOPzY.mp4"}], "aspect_ratio": [1, 1], "duration_millis": 46880}, "media_url": "http://pbs.twimg.com/ext_tw_video_thumb/955947163317612546/pu/img/udGbjDJRKhE2w4ux.jpg", "display_url": "pic.twitter.com/dZAZr7TOHe", "indices": [146, 169], "expanded_url": "https://twitter.com/ABC/status/955947308822204416/video/1", "id": 955947163317612546, "id_str": "955947163317612546", "url": "https://t.co/dZAZr7TOHe"}]}, "entities": {"media": [{"sizes": {"medium": {"w": 720, "resize": "fit", "h": 720}, "thumb": {"w": 150, "resize": "crop", "h": 150}, "large": {"w": 720, "resize": "fit", "h": 720}, "small": {"w": 680, "resize": "fit", "h": 680}}, "type": "video", "media_url_https": "https://pbs.twimg.com/ext_tw_video_thumb/955947163317612546/pu/img/udGbjDJRKhE2w4ux.jpg", "video_info": {"variants": [{"bitrate": 256000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/240x240/HjU2fIlPjNSOwWWm.mp4"}, {"bitrate": 832000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/480x480/2Cj1P2M525Ohszg_.mp4"}, {"content_type": "application/x-mpegURL", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/pl/XH3mVSMfnL9JDdqZ.m3u8"}, {"bitrate": 1280000, "content_type": "video/mp4", "url": "https://video.twimg.com/ext_tw_video/955947163317612546/pu/vid/720x720/NcDTqJ8UUzaYOPzY.mp4"}], "aspect_ratio": [1, 1], "duration_millis": 46880}, "media_url": "http://pbs.twimg.com/ext_tw_video_thumb/955947163317612546/pu/img/udGbjDJRKhE2w4ux.jpg", "display_url": "pic.twitter.com/dZAZr7TOHe", "indices": [146, 169], "expanded_url": "https://twitter.com/ABC/status/955947308822204416/video/1", "id": 955947163317612546, "id_str": "955947163317612546", "url": "https://t.co/dZAZr7TOHe"}], "hashtags": [], "symbols": [], "user_mentions": [], "urls": [{"indices": [122, 145], "expanded_url": "http://abcn.ws/2E4RE3C", "display_url": "abcn.ws/2E4RE3C", "url": "https://t.co/yWc8M74ueK"}]}}, "retweet_count": 1141, "id_str": "955947308822204416", "place": null, "in_reply_to_status_id": null, "favorited": false, "quote_count": 2083, "contributors": null}, "in_reply_to_status_id": null, "favorited": false, "quote_count": 0, "contributors": null}
Option #2
Using the Filter (streaming) API
Collect using terms or hashtags:
$ twarc filter vancouver,toronto > vancouver_tweets.jsonl
Collect using a bounding box:
$ twarc filter --location "\-123.27,49.195,-123.020,49.315" > vancouver_location_tweets.jsonl
Collect new tweets from a given user:
$ twarc filter --follow 255681367 > ian.jsonl
Be creative, and combine them!
$ twarc filter yolo --location "\-123.27,49.195,-123.020,49.315" > vancouver_yolo_tweets.jsonl
Option #3
Using the Search API
Search and collect using terms or hashtags:
$ twarc search vancouver > vancouver_search_tweets.jsonl
$ twarc search "#vancouver OR #toronto" > van_tor_search_tweets.jsonl
Search and collect tweets to a user:
$ twarc search 'to:realdonaldtrump' > donald_search_tweets.jsonl
Search and collect tweets in a geographic area:
$ twarc search --geocode 49.246292,-123.116226,20km > vancouver_geo_search_tweets.jsonl
Be creative, and combine them!
$ twarc search 'trump to:JustinTrudeau' --geocode 49.246292,-123.116226,100km > justin_search_tweets.jsonl
Option #4
Download some!
DocNow Catalog
Internet Archive
Other considerations
You have a log! Logs are great!
$ tail -f twarc.log
2018-01-25 12:18:32,439 INFO archived 956527929663438848
2018-01-25 12:18:32,439 INFO archived 956527925968322561
2018-01-25 12:18:32,439 INFO getting ('https://api.twitter.com/1.1/search/tweets.json',) {'params': {'tweet_mode': 'extended', 'geocode': '49.246292,-123.116226,20km', 'max_id': '956527925968322560', 'result_type': 'recent', 'count': 100, 'q': ''}}
2018-01-25 12:18:32,507 WARNING rate limit exceeded: sleeping 799.4925899505615 secs
2018-01-25 12:26:29,356 INFO loading main profile from config /home/nruest/.twarc
2018-01-25 12:26:29,356 INFO creating http session
2018-01-25 12:26:29,356 INFO getting ('https://api.twitter.com/1.1/search/tweets.json',) {'params': {'q': 'trump to:JustinTrudeau', 'count': 100, 'result_type': 'recent', 'geocode': '49.246292,-123.116226,100km', 'tweet_mode': 'extended'}}
2018-01-25 12:26:29,596 WARNING rate limit exceeded: sleeping 322.40351009368896 secs
2018-01-25 12:31:52,096 INFO getting ('https://api.twitter.com/1.1/search/tweets.json',) {'params': {'q': 'trump to:JustinTrudeau', 'count': 100, 'result_type': 'recent', 'geocode': '49.246292,-123.116226,100km', 'tweet_mode': 'extended'}}
2018-01-25 12:31:52,171 WARNING rate limit exceeded: sleeping 10 secs
2018-01-25 12:32:02,174 INFO getting ('https://api.twitter.com/1.1/search/tweets.json',) {'params': {'q': 'trump to:JustinTrudeau', 'count': 100, 'result_type': 'recent', 'geocode': '49.246292,-123.116226,100km', 'tweet_mode': 'extended'}}
2018-01-25 12:32:02,343 INFO archived 956229309949030400
2018-01-25 12:32:02,344 INFO archived 955740952378859520
2018-01-25 12:32:02,344 INFO archived 955546566219018240
2018-01-25 12:32:02,344 INFO archived 954440037407453184
2018-01-25 12:32:02,344 INFO archived 954401509805969408
2018-01-25 12:32:02,344 INFO archived 954400625806032899
2018-01-25 12:32:02,344 INFO getting ('https://api.twitter.com/1.1/search/tweets.json',) {'params': {'geocode': '49.246292,-123.116226,100km', 'q': 'trump to:JustinTrudeau', 'count': 100, 'result_type': 'recent', 'tweet_mode': 'extended', 'max_id': '954400625806032898'}}
2018-01-25 12:32:02,458 INFO no new tweets matching {'geocode': '49.246292,-123.116226,100km', 'q': 'trump to:JustinTrudeau', 'count': 100, 'result_type': 'recent', 'tweet_mode': 'extended', 'max_id': '954400625806032898'}
Check out the help
optional arguments:
-h, --help show this help message and exit
--log LOG log file
--consumer_key CONSUMER_KEY
Twitter API consumer key
--consumer_secret CONSUMER_SECRET
Twitter API consumer secret
--access_token ACCESS_TOKEN
Twitter API access key
--access_token_secret ACCESS_TOKEN_SECRET
Twitter API access token secret
--config CONFIG Config file containing Twitter keys and secrets
--profile PROFILE Name of a profile in your configuration file
--warnings Include warning messages in output
--connection_errors CONNECTION_ERRORS
Number of connection errors before giving up
--http_errors HTTP_ERRORS
Number of http errors before giving up
--max_id MAX_ID maximum tweet id to search for
--since_id SINCE_ID smallest id to search for
--result_type {mixed,recent,popular}
search result type
--lang LANG limit to ISO 639-1 language code
--geocode GEOCODE limit by latitude,longitude,radius
--locations LOCATIONS
limit filter stream to location(s)
--follow FOLLOW limit filter to tweets from given user id(s)
--recursive also fetch replies to replies
--tweet_mode {compat,extended}
set tweet mode
--output OUTPUT write output to file path
--format {json,csv} set output format
--split SPLIT used with --output to split into numbered files
Want metadata for a given user?
$ twarc users ruebot
{"verified": false, "name": "417 Expectation Failed", "time_zone": "Eastern Time (US & Canada)", "lang": "en", "suspended": false, "favourites_count": 11388, "default_profile_image": false, "is_translation_enabled": false, "profile_text_color": "333333", "geo_enabled": true, "contributors_enabled": false, "followers_count": 1746, "translator_type": "regular", "listed_count": 157, "status": {"favorited": false, "lang": "und", "display_text_range": [13, 36], "geo": null, "full_text": "@deantiquate https://t.co/STVz1Zx582", "created_at": "Thu Jan 25 04:31:42 +0000 2018", "in_reply_to_user_id": 158937744, "contributors": null, "is_quote_status": false, "id_str": "956384057872576512", "source": "Fenix 2", "possibly_sensitive": false, "in_reply_to_user_id_str": "158937744", "in_reply_to_status_id_str": "956364465674452992", "favorite_count": 0, "retweet_count": 0, "truncated": false, "in_reply_to_status_id": 956364465674452992, "coordinates": null, "place": null, "id": 956384057872576512, "entities": {"symbols": [], "user_mentions": [{"indices": [0, 12], "id_str": "158937744", "name": "Anna St.Onge", "screen_name": "deantiquate", "id": 158937744}], "hashtags": [], "urls": [{"display_url": "youtu.be/oQwNN-0AgWc", "indices": [13, 36], "url": "https://t.co/STVz1Zx582", "expanded_url": "https://youtu.be/oQwNN-0AgWc"}]}, "in_reply_to_screen_name": "deantiquate", "retweeted": false}, "id": 24092133, "profile_link_color": "050505", "notifications": false, "profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme19/bg.gif", "follow_request_sent": false, "is_translator": false, "friends_count": 956, "profile_background_image_url": "http://abs.twimg.com/images/themes/theme19/bg.gif", "screen_name": "ruebot", "profile_sidebar_fill_color": "EFEFEF", "url": "https://t.co/PncEcoIUqM", "profile_image_url_https": "https://pbs.twimg.com/profile_images/941691177350307841/_5Y76CrD_normal.jpg", "profile_banner_url": "https://pbs.twimg.com/profile_banners/24092133/1503197535", "needs_phone_verification": false, "id_str": "24092133", "statuses_count": 34304, "profile_background_color": "F0F0F0", "profile_image_url": "http://pbs.twimg.com/profile_images/941691177350307841/_5Y76CrD_normal.jpg", "profile_sidebar_border_color": "FFFFFF", "created_at": "Fri Mar 13 01:11:04 +0000 2009", "utc_offset": -18000, "profile_background_tile": false, "location": "Toronto", "protected": false, "default_profile": false, "entities": {"url": {"urls": [{"display_url": "zortonandthecannibals.com", "indices": [0, 23], "url": "https://t.co/PncEcoIUqM", "expanded_url": "http://zortonandthecannibals.com"}]}, "description": {"urls": [{"display_url": "ruebot.net", "indices": [0, 23], "url": "https://t.co/sXqvoKmfSA", "expanded_url": "http://ruebot.net"}]}}, "profile_use_background_image": false, "description": "https://t.co/sXqvoKmfSA", "has_extended_profile": false, "following": false}
Who follows the user?
$ twarc followers ruebot
86044173
933334441879130112
2196657985
2269836187
943158785111191553
156493032
3529991
1691501
78383277
356831275
Who does the user follow?
$ twarc friends ruebot
6044173
259796590
951095946896588800
223666145
946205176867803136
240483932
909866155296395264
78383277
1691501
3529991
Retweets and Replies
$ twarc retweets 896523232098078720 > 896523232098078720_retweets.jsonl
$ twarc replies 896523232098078720 > 896523232098078720_replies.jsonl
$ twarc replies 896523232098078720 --recursive > 896523232098078720_recursive_replies.jsonl
"No one is born hating another person because of the color of his skin or his background or his religion..." pic.twitter.com/InZ58zkoAm
— Barack Obama (@BarackObama) August 13, 2017
Hydrate and Dehydrate
$ twarc dehydrate justin_search_tweets.jsonl > justin_search_tweet_ids.txt
$ twarc hydrate justin_search_tweet_ids.txt > justin_search_tweets.jsonl
Let's look at the utilities, and maybe do something with this data!
If you haven't already, you'll need to clone, or download the twarc repo to use the utilities:
$ git clone https://github.com/DocNow/twarc.git
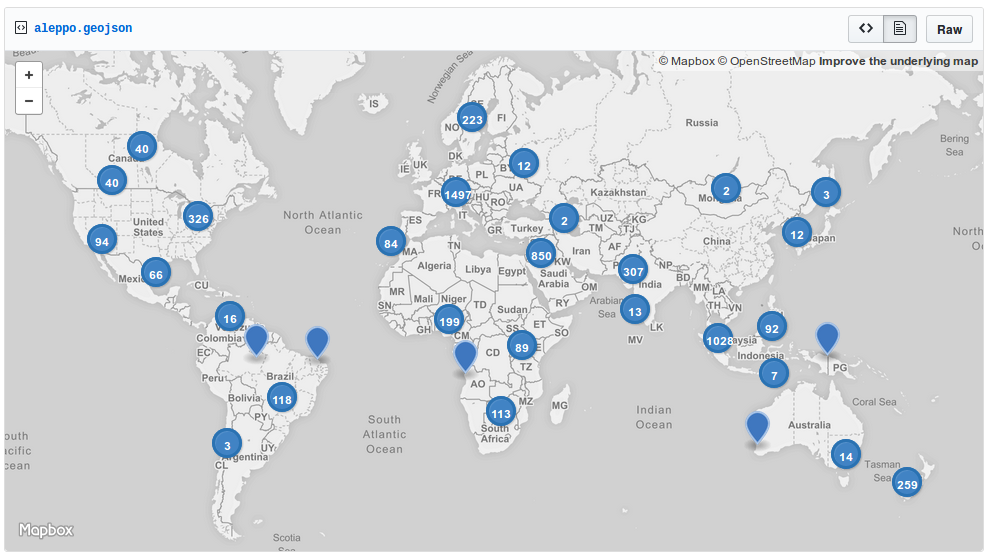
We did some geolocation collection, let's see what it looks like on a map!
$ ~/git/twarc/utils/geojson.py tweets.jsonl > tweets.geojson
If you don't want to mess around with Leaflet, use GitHubGist!
What if you just wanted the text?
$ cat vancouver_geo_search_tweets.jsonl | jq .full_text
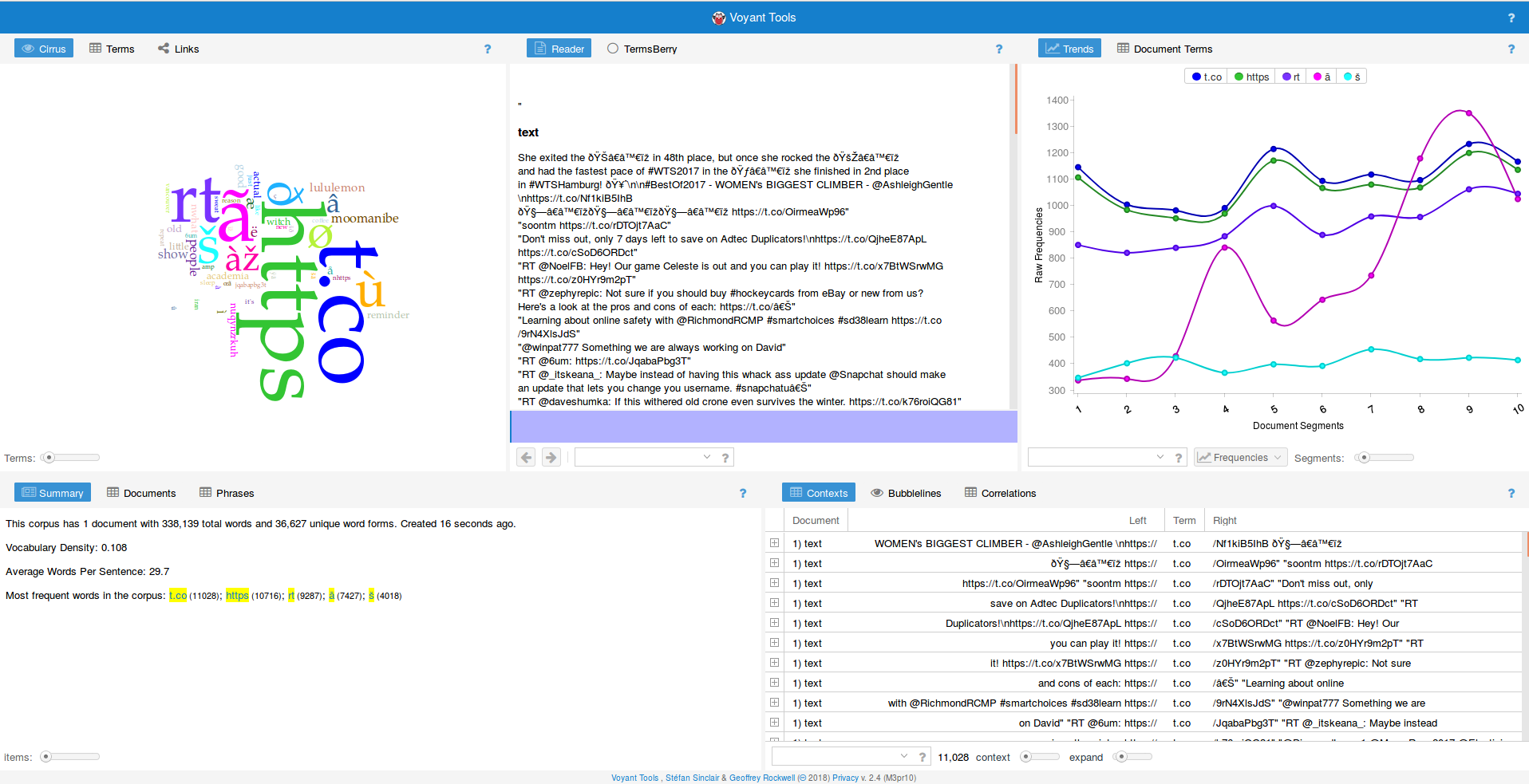
Voyant Tools
What if I wanted all the image urls?
$ ~/git/twarc/image_urls.py tweets.jsonl > images_urls.txt
Oh, can I download them?
cat image_urls.txt | while read line; do wget "$line"; done
Oh, can I get the urls tweeted?
$ ~/git/twarc/urls.py tweets.jsonl > urls.txt
What if I want to filter out tweets by date?
$ ~git/utils/filter_date.py --mindate 25-jan-2018 tweets.jsonl > filtered.jsonl
Now comes the fun part, be creative and ask the data questions!
command line utilities, jq, Python, Pandas, Ruby, aut, etc., these are your friends!