I have to start somewhere, so I'll start here. Almost a year ago, I was in a meeting and was presented with this problem. YFile, a daily university newspaper (used to be a paper now a website) had been taken over my marketing a while back, and they deleted all their back content. They are an official university publication, so an official university record, and eventual end up in archives, so it will eventually be our problem; the library's problems. Plainly put, we live in a reality where official records are born and disseminated via the Internet. Many institutions have a strategy in place for transferring official university records that are print or tactile to university archives, but not much exists strategy-wise for websites. So, I naively decided to tackle it.

I tend to just do things. I don't ask permission. I apologize later if i have to (like taking down the YFile server). If i make mistakes, good (crawling incorrectly, not knowing to use page requisites, mirror doesn't grab everything!)! Then I've learned something. What i am doing isn't new, but then again it knda is. It is a really weird place. I need to crawl a website or everyday. The internet archive comes around whenever it does. There is no way to give the Internet Archive/Wayback machine a whole bunch of warc files, and I'm not going to pay for Archive-It.

That won't work for me at all when I have some idea how to do it all myself. So, what is the problem? I need to capture and preserve a website everyday. I want to provide the best material to a researcher. I want to keep a fine eye on preservation, but not be a digital pack rat, and need to constantly keep the librarian and archivist in be pleased. Which is always Item vs. collection debate and which of those gets the most attention.

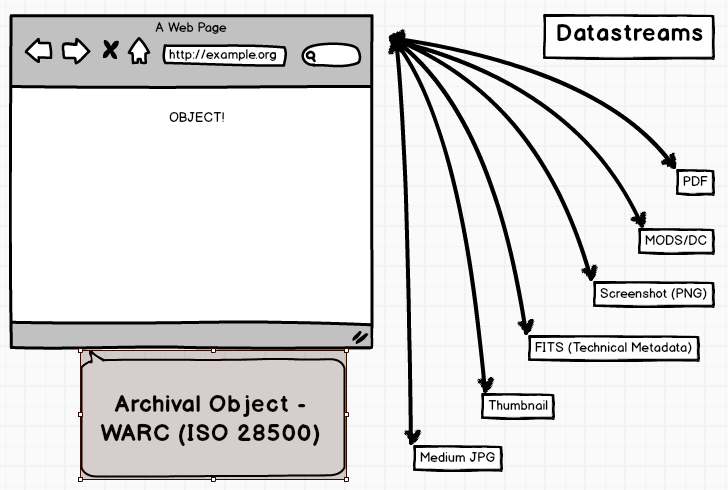
How many people here know what a warc is? Warc stands for web archive. It is an iso standard. It is basically a file (that can get massive very quickly) that aggregates resources you request into a single file along with crawl metadata, checksums. PROVENANCE! This is what the beginning of a warc file looks like.

So, warcs are a little weird to deal with on their own. You can disseminate them with Wayback Machine, and I assume nobody but a few people on this planet want to see a page full of just warc files. Building something browsable takes a little bit more work. So, I decided to snag a pdf and screenshot of the page or frontpage of the site that I am grabbing with wkhtmltopdf and image. Then I toss this all in a single bash script, and give it to cron.

collection object (parent)
collection object (object/site)
object (crawl)
Here is what my object looks like. Explain it a bit.
now for something different.
As I was working on this web archiving stuff, and slowly building a Web ARChive solution pack for Islandora, this guy happened. Dale is my former boss, and a great guy. Through all of the chaos and bullshit at McMaster, we were able to rise above it and forge a great relationship. So, when he put out a call for help, I jumped up immediately and volunteered to take care of web archiving.

I started with the initial list of sites that John Dupuis pulled together, and crawled it a single time, all by hand! Talk about a lesson learned! Then I thought about it a bit, and talked to Dale, and figured that we should just capture these everyday. Create a record, an archive, of this still unfolding story. To see if anything is taken down. How comments unfold over time. How associations and organizations don't understand that COOL URLS DO NOT CHANGE! But, really just to document this. Because we can. We have the power.

So, what I did is start yet another little pet project. The wonderful Sarah Shujah organized a hackfast during reading week, and I just hunkered down and tossed together a shell script using what I learned from the YFile stuff that just parsed a text file list of all the sites John Dupuis and I could find about this story.

Then one day at a PLG meeting, I proposed that we do something with this collection. Make it available! Then with the wonder assistance of Anna St. Onge & Jacqueline Whyte Appleby we have been slowly organizing and describing this collection using the solution pack I created for Islandora and AtoM (access to memory) for creating archival descriptions.
Anna has been doing the heavy lifting here as far as content. Creating authority records, and working on descriptions. This is where a lot of new problems and old problems popup, where should something live and how to pull something from something else if it lives somewere else.
Now the stuff I'm not good at. I do activism. I do social justice. But, I'm horrible at explaining the why. But, I'll give it shot.

I really take to heart the social justice and social responsibility, and I believe it goes hand-in-hand with the ethics of our profession. This is why I helped found a local PLG chapter with a bunch of other amazing library workers. We are Toronto-area library workers who are concerned with social justice and equality issues, charged with the stewardship of knowledge, championing open access to information, and preserving common space. We are interested in issues of freedom of expression, attacks on Canadian heritage, freedom of information, privacy, censorship, copyright, equitable access to information, the fostering of critical information literacy, and the broad social implications of the commodification of information and increasing corporate influence on libraries. As library workers, we recognize that the increasing lack of job security, de-professionalization, and casualization of our profession threatens the “free public sphere which makes an independent democratic civil society possible.”
Questions?
