Biography
Nick Ruest is an Associate Librarian in the Digital Scholarship Infrastructure Department at York University. At York University, he oversees the library’s preservation initiatives, along with creating and implementing systems that support the capture, description, delivery, and preservation of digital objects having significant content of enduring value.
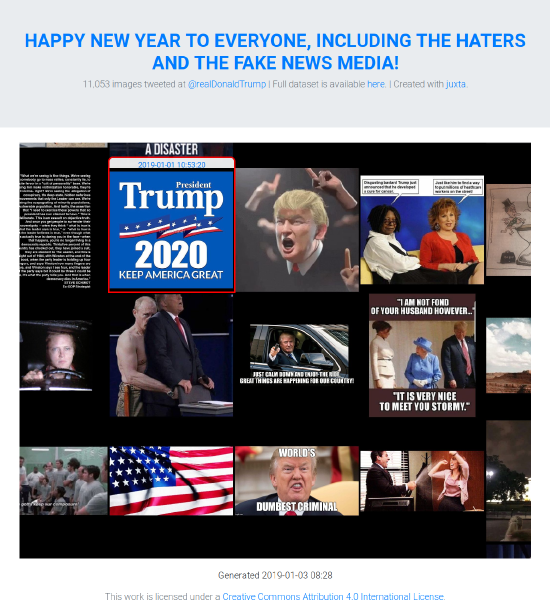
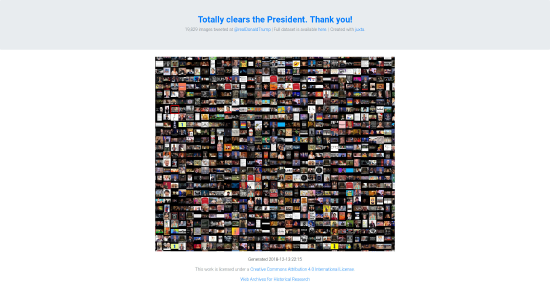
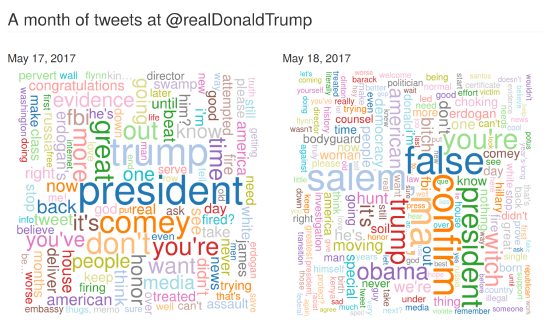
His research portfolio has focused on developing and supporting computational research tools and methodologies for web archives. He was the co-Principal Investigator of the Andrew W. Mellon Foundation-funded The Archives Unleashed Project from 2017-2023 (the project lives on as an Internet Archive service), co-Principal Investigator of the SSHRC grant “A Longitudinal Analysis of the Canadian World Wide Web as a Historical Resource, 1996-2014” from 2015-2021, and co-Principal Investigator of the Compute Canada Research Platforms and Portals Web Archives for Longitudinal Knowledge from 2016-2020.
He was previously active in the Islandora and Fedora communities, serving as Project Director for the Islandora CLAW project, a member of the Islandora Foundation’s Roadmap Committee and Board of Directors, and contributed code to the project. He has also served as the Release Manager for Islandora and Fedora, the moderator for the OCUL Digital Curation Community, the President of the Ontario Library and Technology Association, and President of McMaster University Academic Librarians’ Association.
Interests
- Web archives
- Data analytics
- Distributed systems
- Information retrieval
- Digital preservation
Education
-
MLIS, 2007
Wayne State University
-
Bachelor of Arts Political Science, Minor in History, 2004
University of Michigan-Dearborn